使用正则表达式从文件名中获取标题和年份
我如何编写一个正则表达式来获取标题,如果可用的话,从文件名中获取年份?见下面的例子.
这个解决方案适用于PHP但我有问题将其翻译成javascript Seprate电影名称和年份来自moviefile名称
The.Great.Gatsby.2013.BluRay.1080p.DTS.x264-CHD.mkv
The Forbidden Girl 2013 BRRIP Xvid AC3-BHRG.avi
Pain.&.Gain.2013.720p.BluRay.DD5.1.x264-HiDt.mkv
Se7en.avi
Se7en.(1995).avi
How to train your dragon 2.mkv
10,000BC (2010).1080p.avi
下面提供的解决方案适用于您提供的所有测试用例(以及一些额外的标题,请参阅下面的代码),并且可以自定义。
长话短说,尝试下面的代码片段:
// Live Test
var input = document.getElementById('input');
var output = document.getElementById('output');
input.oninput = function() { output.textContent = extractData(input.value); }
// Samples
var tests = ['The.Great.Gatsby.2013.BluRay.1080p.DTS.x264-CHD.mkv', 'The Forbidden Girl 2013 BRRIP Xvid AC3-BHRG.avi', 'Pain.&.Gain.2013.720p.BluRay.DD5.1.x264-HiDt.mkv', 'Se7en.(1995).avi', 'How to train your dragon 2.mkv', '10,000BC (2010).1080p.avi', 'The.Great.Gatsby.BluRay.1080p.DTS.x264-CHD.mkv', 'Se7en.avi', '2001 A Space Odyssey.BluRay.1080p.DTS.x264-CHD.mkv','Sand.Castle.2017.FRENCH.1080.WEBRip.AAC2.0-NEWCiNE-WwW.Zone-Telechargement.Ws.mkv'];
while (t = tests.pop()) {
document.getElementById('list').innerHTML += '<b>INPUT</b>: "' + t + '"<br>';
document.getElementById('list').innerHTML += extractData(t,true) + '<hr>';
}
function titlelize(title) {
return title.replace(/(^|[. ]+)(\S)/g, function(all, pre, c) { return ((pre) ? ' ' : '') + c.toUpperCase(); });
};
function extractData(it, html) {
var regex = /^(.+?)[.( \t]*(?:(19\d{2}|20(?:0\d|1[0-9])).*|(?:(?=bluray|\d+p|brrip|webrip)..*)?[.](mkv|avi|mpe?g|mp4)$)/i;
var out = '↳ ';
if ( m = regex.exec(it) ) {
title = titlelize(m[1]) || '-'; year = m[2] || '-';
out += '<font color="green"><b>Title</b>: "' + title +
'"  <b>Year</b>: "' + year + '"</font>';
} else {
out += '<font color="red">No match</font>';
}
//the replace is an hack to remove html in live input text
return (html) ? out : out.replace(/<[^>]+>|&[^;]+;/g,'');
}<mark><b>Paste and Try!</b></mark> ⇒ <input id="input" type="text" size="70" />
<br>↳ <span id="output" style="line-height:40px;">No Match</span>
<hr>
<div id="list"></div>描述
假设标题的结构大致如下:
标题* || [年份* ] || [ Codec ]扩展
方括号内的字段是可选的(例如 [ field1 ])
* :保存的字段
关键是将所有内容匹配为标题,直到找到的最后一个有效年份(有效年份:1900-2016)或直到文件扩展名(结构为一个点加 3 个字母,如果需要,可以轻松更改)。
例外:如果电影不包含以(不区分大小写)bluray或[0-9]+p(例如720p,1080p)开头的有效年份,或者从标题brrip部分中删除。
正则表达式突破 Regex101 Demo
/^
(.+?) # Save title into group $1
[.( \t]* # Remove some separators
(?: # Non capturing group
(19\d{2}|20(?:0\d|1[0-6])).* # Save years (1900-2016) in $2
| # OR
(?:(?=bluray|\d+p|brrip)..*)? # Match string starting with bluray,brrip,720p...
[.](mkv|avi|mpe?g)$) # Match extension (.mkv,.avi.,mpeg) add your own
/i # make the regex case insensitive
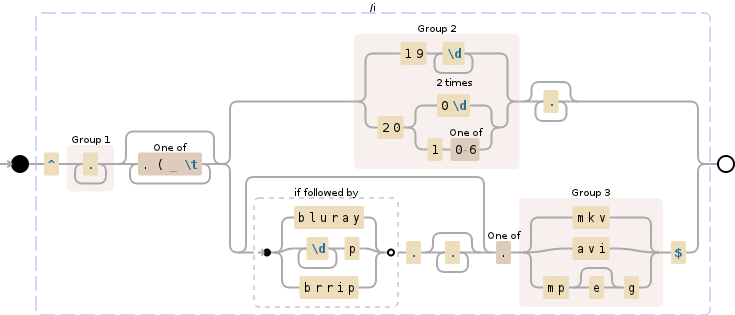
正则表达式定制
异常和扩展列表可以在测试期间轻松地在需要时一点一点地填充新值(作为文件扩展名,例如将它们添加.wmv和.flv添加到(mkv|avi|mpe?g|wmv|flv)正则表达式的部分)或使部分通用将其替换为[.]\w{3,4}$.