MapReduce 2对YARN应用程序
Fra*_*ran 4 mapreduce hadoop-yarn hadoop2
关于如何开发新的MapReduce2应用程序以与YARN一起工作以及旧的应用程序会发生什么,我有点困惑.
我目前有MapReduce1应用程序,主要包括:
- 配置要提交到集群的作业的驱动程序(以前的JobTracker和现在的ResourceManager).
- Mappers + Reducers
从一方面我看到MapReduce1中编码的应用程序在MapReduce2/YARN中是兼容的,有一些注意事项,只需重新编译新的CDH5库(我使用Cloudera发行版).
但是从另一方面来说,我看到有关以与MapReduce不同的方式编写YARN应用程序的信息(使用YarnClient,ApplicationMaster等):
http://hadoop.apache.org/docs/r2.7.0/hadoop-yarn/hadoop-yarn-site/WritingYarnApplications.html
但对我来说,YARN只是架构以及集群如何管理您的MR应用程序.
我的问题是:
YARN申请是否包括MapReduce申请?- 我应该像
YARN应用程序一样编写代码,忘记驱动程序和创建Yarn客户端ApplicationMasters等等吗? - 我还可以使用驱动程序+作业设置开发客户端类吗?是
MapReduce1(使用MR2库重新编译)作业YARN以与YARN应用程序相同的方式管理? MapReduce1应用程序和YARN应用程序之间在YARN内部管理它们的方式有何不同?
提前致谢
小智 6

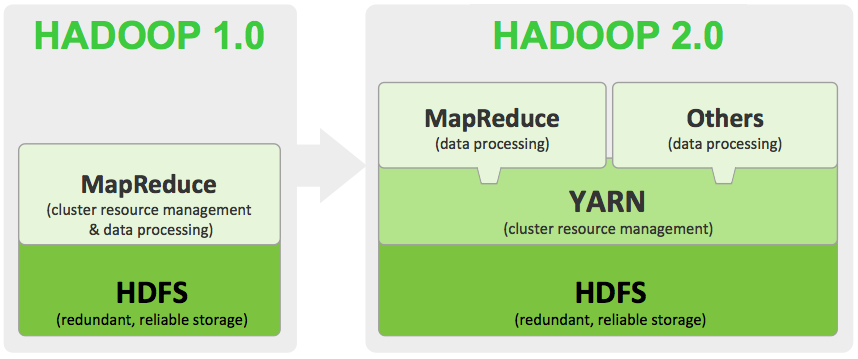
HADOOP版本1
JobTracker负责资源管理---管理从节点---主要功能涉及
- 跟踪资源消耗/可用性
- 工作生命周期管理---安排工作的个人任务,跟踪进度,为任务提供容错能力.
Hadoop v1 JobTracker的问题负责所有衍生的MR应用程序,这是单点故障---如果JobTracker发生故障,集群中的所有应用程序都将被终止.此外,如果集群有大量应用程序,JobTracker成为性能瓶颈,解决Hadoop v2发布的可伸缩性和作业管理问题.
Hadoop v2
YARN的基本思想是将Job-Tracker的两个主要职责 - 即资源管理和作业调度/监控 - 分成单独的守护进程:全局ResourceManager和每个应用程序ApplicationMaster(AM).ResourceManager和每个节点的从属服务器NodeManager(NM)构成了一个新的通用操作系统,用于以分布式方式管理应用程序.
为了与新的资源管理和调度交互,开发了一个Hadoop YARN mapReduce应用程序--- MRv2与mapReduce编程API无关
应用程序员将看到MRv1和MRv2之间没有区别,MRv2完全向后兼容---是MR应用程序(.jar),可以在两个框架上运行而无需更改代码.
Hadoop 2.x已包含MR Client和AppMaster的代码,程序员只需关注他们的MapReduce应用程序.
MapReduce之前已集成在Hadoop Core中 - 唯一与HDFS中的数据交互的API.现在在Hadoop v2中,它作为单独的应用程序运行,Hadoop v2允许其他应用程序编程框架(例如MPI)处理HDFS数据.