从R中的列表中除了特定正则表达式之外的所有内容
我想替换一个与给定模式不匹配的列表中的所有内容.我正在使用R版本3.1.3(2015-03-09) - "光滑的人行道"
我的示例列表是:
y <- c("D CCNA_01234 This is example 1 bis", "D CCNA_02345 This is example 2", "D CCNA_12345 This is example 3", "D CCNA_23468 This is example 4")
我要匹配的模式是CCNA_01234,其中数字在每种情况下都不相同,但总是5位数.
所需的输出是:
"CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
到目前为止,我已经删除了前一部分的比赛:
y_begin_rm <- sub("D ", "", y)
但我在识别匹配[^ match]表达式时遇到了问题.
y_CCNA_numbers <- sub("[^CCNA_[0-9][0-9][0-9][0-9][0-9]]*$", "", y_begin_rm)
产生输出:
[1] "CCNA_01234 This is example 1 bis" "CCNA_02345 This is example 2"
[3] "CCNA_12345 This is example 3" "CCNA_23468 This is example 4"
似乎问题是匹配中指定的数字完全通过字符串查看,而不是我想要的确切组合.因此,"这是一个例子"之后的数字正在造成很多麻烦.当我省略数字或放置一个仅在CCNA_string之后的数字时,它可以正常工作:
y_CCNA <- sub("[^CCNA_]*$", "", y_begin_rm)
报复
[1] "CCNA_" "CCNA_" "CCNA_" "CCNA_"
要么
y_CCNA_0 <- sub("[^CCNA_0]*$", "", y_begin_rm[1])
结果是
[1] "CCNA_0"
有没有办法指定我正在寻找的确切模式(CCNA_ [0-9] [0-9] [0-9] [0-9] [0-9])?此外,是否有可能在一个步骤中执行此操作(在单个正则表达式中匹配之前和之后删除)?
提前致谢!
使用基础R,您可以直接从原始向量进行操作 y
sub(".*(CCNA_\\d+).*", "\\1", y)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
另一种选择是使用 stringi
library(stringi)
stri_extract_first_regex(y, "CCNA_\\d+")
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
如果您CCNA在每个字符串中使用多个模式,请stri_extract_all_regex改为使用
如果你想匹配正好 5位数字后CCNA_,你还可以做
stri_extract_first_regex(y, "CCNA_\\d{5}")
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
当然也有类似的 stringr
library(stringr)
str_extract(y, "CCNA_\\d{5}")
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
以下是几种方法:
1)strapplyc.这使用了一种特别简单的模式.它strapplyc在gsubfn包中使用:
library(gsubfn)
strapplyc(y, "CCNA_\\d{5}", simplify = TRUE)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
这是正则表达式的可视化:
CCNA_\d{5}
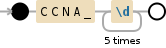
1a) 如果CCNA_的唯一出现在5位之前,那么我们可以稍微简化以前的解决方案:
strapplyc(y, "CCNA_.{5}", simplify = TRUE)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
2)分.这里的模式稍微复杂一点,但使用sub我们可以在没有任何插件包的情况下完成:
sub(".*(CCNA_\\d{5}).*", "\\1", y)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
3)strsplit如果所需的部分总是第二个"单词"(在问题中是这种情况)那么这将起作用并且再次不需要包:
sapply(strsplit(y, " "), "[", 2)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
4)substr如果所需部分始终是问题中的字符3到12,那么我们可以使用substr或者substring再次使用没有任何包:
substr(y, 3, 12)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"