了解 Neil Fraser 的差分同步算法
Mår*_*röm 5 algorithm synchronization
我试图完全理解差分同步算法,特别是保证交付方法(第 4 节)。
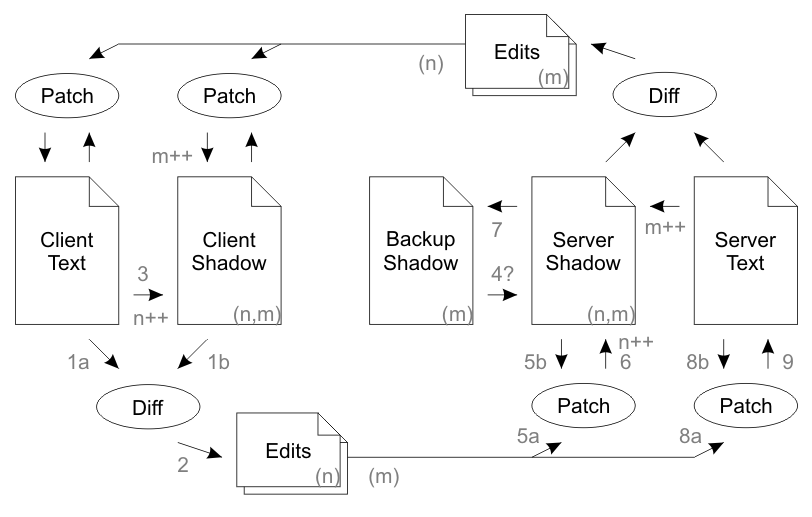
我不明白为什么在同步周期的上半部分需要编辑堆栈。
编辑堆栈的用途如下(复制自第 4 节第二段):
[...] 在丢包的情况下,编辑内容会在堆栈中排队,并在每次同步时重新传输到远程方,直到远程方返回接收确认。
这就说得通了。但在第六段的后面(丢失返回数据包的情况)它说:
这表明之前的响应肯定已经丢失。因此,服务器删除其编辑堆栈并将备份阴影复制到阴影文本中(步骤 4)。
所以,据我了解:
在正常操作期间:编辑堆栈(在上半部分)将包含一个条目,该条目将在下一个同步周期期间被确认并删除。
如果出现网络错误:客户端无法确认编辑堆栈,服务器将简单地清除它。
如果这是正确的,则上半部分的编辑堆栈将是空的或包含单个条目。此外,在任何情况下,该单个条目都不会(重新)发送回客户端。让它完全没用?!
显而易见的问题是,为什么我们需要一个编辑堆栈(在上半部分)?
我确信我错过了一些重要的事情。请帮帮我。
小智 3
您的观点对于客户端-服务器架构来说是有效的。服务器的Edits堆栈是更通用的对称表示的延续,其中客户端和服务器具有相同的功能和结构(特别是,任何一方都可以发起通信)。虽然理想情况下将客户端Backup Shadow放在客户端-服务器设置中以节省空间/时间,但客户端Edits仍然可以使用堆栈数据结构,没有任何缺点,并且具有一致的 API 的优点。请注意,该算法可以追溯到 2009 年左右。今天(2017 年),您可能会选择使用 WebSockets 或 WebRTC。差分同步算法预期并适应这样的设置,其中双方本质上是对等的并遵循相同的协议。