如何在Google BigQuery中的URL字符串中的模式之后使用SYMBOLS提取字符串
she*_*ode 4 regex string pattern-matching google-bigquery
我有两种可能的URL字符串形式
http://www.abcexample.com/landpage/?pps=[Y/lyPw==;id_1][Y/lyP2ZZYxi==;id_2];[5403;ord];
http://www.abcexample.com/landpage/?pps=Y/lyPw==;id_1;unknown;ord;
我想Y/lyPw==在两个例子中得出结论
所以;id_1括号之间的所有内容
将永远属于该?pps=部分
解决这个问题的最佳方法是什么?我想使用大查询语言,因为这是我的数据所在
以下是构建正则表达式的一种方法:
SELECT REGEXP_EXTRACT(url, r'\?pps=;[\[]?([^;]*);') FROM
(SELECT "http://www.abcexample.com/landpage/?pps=;[XYZXYZ;id_1][XYZZZZ;id_2];[5403;ord];"
AS url),
(SELECT "http://www.abcexample.com/landpage/?pps=;XYZXYZ;id_1;unknown;ord;"
AS url)
你可以使用这个正则表达式:
pps=\[?([^;]+)
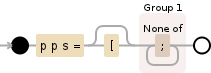
这个正则表达式背后的想法是:
pps= -> Look for the pps= pattern
\[? -> might have a [ or not
([^;]+) -> store the content up to the first semi colon
因此,对于您的两个网址,此正则表达式将匹配(蓝色)和捕获(绿色),如下所示:

对于BigQuery,你必须使用
REGEXP_EXTRACT('str', 'reg_exp')
引用其文档:
REGEXP_EXTRACT:返回与正则表达式中的捕获组匹配的str部分.
你必须使用这样的代码:
SELECT
REGEXP_EXTRACT(word,r'pps=\[?([^;]+)') AS fragment
FROM
...
对于工作示例代码,您可以使用:
SELECT
REGEXP_EXTRACT(url,r'pps=\[?([^;]+)') AS fragment
FROM
(SELECT "http://www.abcexample.com/landpage/?pps=;[XYZXYZ;id_1][XYZZZZ;id_2];[5403;ord];"
AS url),
(SELECT "http://www.abcexample.com/landpage/?pps=;XYZXYZ;id_1;unknown;ord;"
AS url)