如何在R中构造和重新编码混乱的分类数据?
我正在努力解决如何最好地构建混乱的分类数据,并且来自我需要清理的数据集.
编码方案
我正在分析大学科学课程考试的数据.我们正在研究学生反应中的模式,我们开发了一种编码方案来表示学生在答案中所做的事情.编码方案的子集如下所示.
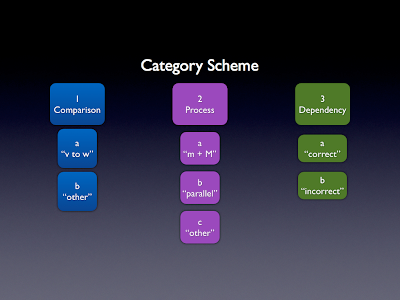
注意,在每个主要代码(1,2,3)内是嵌套的非唯一子代码(a,b,...).
原始数据看起来像什么
我已经创建了一个我的实际数据的匿名原始子集,您可以在此处查看.我的部分问题是编码数据的人注意到一些学生显示了多种模式.该编码器的解决方案是建立足够的列(reason1,reason2,...),让学生理解使用多种模式.这变得很重要,因为顺序(reason1,reason2)是任意的 - 正确应用"依赖"的两个学生(如我的数据集中的学生41和学生42
)应该在分析中注册,无论是3a出现在reason列还是reason2列中.
我如何才能最好地构建学生数据?
我的部分问题是,在原始数据中,并非所有学生都以相同的顺序显示相同的模式或相同数量的模式.有些学生可能只做一件事,有些可能做几件.因此,示例学生的抽象表示可能如下所示:

请注意,在上面的示例中student002,student003两者都被编码为"1b",尽管我故意将顺序显示为不同以反映我的数据的实际情况.
我的(实际)问题
- 我应该串联
reason1,reason2,...成一列? - 我如何(重新)编写
reasonR中的s以反映某些学生的多样性?
谢谢
我意识到这个问题与良好的数据概念化同样重要,因为它与R的特定功能有关,但我认为在这里提出它是合适的.如果您觉得我提出这个问题是不合适的,请在评论中告诉我,stackoverflow会自动使用sadface表情符号填充我的收件箱.如果我不够具体,请告诉我,我会尽力让自己更清楚.
让它"长":
library(reshape)
dnow <- read.csv("~/Downloads/catsample20100504.csv")
dnow <- melt(dnow, id.vars=c("Student", "instructor"))
dnow$variable <- NULL ## since ordering does not matter
subset(dnow, Student%in%c(41,42)) ## see the results
下一步做什么将取决于您想要做的分析类型.但是长格式对于像你这样的不规则数据很有用.
- 每个响应的频率`表(dnow $ value)`,以及"哪些学生有特定的回应?" `with(dnow,sort(Student [value =="3a"]))`可能是分析的好开始问题. (2认同)
- briandk - `%in%`基本上是`match()`的二进制接口,你实际上可以查找?match(与%in%不同).基本上,你给它左边的值向量和右边的值向量,它会给你一个逻辑向量,指示左手向量中的哪些值在右手中.在Eduardo的代码中,它给`subset()`一个TRUE和FALSE的向量,以指示哪些行是学生41和42. (2认同)
| 归档时间: |
|
| 查看次数: |
902 次 |
| 最近记录: |