如何使用Node.js在MongoDB中使用cursor.forEach()?
use*_*786 49 mongoose mongodb node.js
我的数据库中有大量文档,我想知道如何浏览所有文档并更新它们,每个文档都有不同的值.
Leo*_*tny 111
答案取决于您使用的驱动程序.我所知道的所有MongoDB驱动程序都以cursor.forEach()这种或那种方式实现.
这里有些例子:
节点MongoDB的原生
collection.find(query).forEach(function(doc) {
// handle
}, function(err) {
// done or error
});
mongojs
db.collection.find(query).forEach(function(err, doc) {
// handle
});
僧
collection.find(query, { stream: true })
.each(function(doc){
// handle doc
})
.error(function(err){
// handle error
})
.success(function(){
// final callback
});
猫鼬
collection.find(query).stream()
.on('data', function(doc){
// handle doc
})
.on('error', function(err){
// handle error
})
.on('end', function(){
// final callback
});
更新.forEach回调内的文档
更新.forEach回调文档的唯一问题是您不知道何时更新所有文档.
要解决此问题,您应该使用一些异步控制流解决方案.以下是一些选项:
以下是async使用其queue功能的使用示例:
var q = async.queue(function (doc, callback) {
// code for your update
collection.update({
_id: doc._id
}, {
$set: {hi: 'there'}
}, {
w: 1
}, callback);
}, Infinity);
var cursor = collection.find(query);
cursor.each(function(err, doc) {
if (err) throw err;
if (doc) q.push(doc); // dispatching doc to async.queue
});
q.drain = function() {
if (cursor.isClosed()) {
console.log('all items have been processed');
db.close();
}
}
- 对于猫鼬来说只是一个小注释 - 不推荐使用`.stream`方法,现在我们应该使用`.cursor` (4认同)
chr*_*953 16
使用mongodb驱动程序以及具有异步/等待功能的现代NodeJS,一个好的解决方案是使用next():
const collection = db.collection('things')
const cursor = collection.find({
bla: 42 // find all things where bla is 42
});
let document;
while ((document = await cursor.next())) {
await collection.findOneAndUpdate({
_id: document._id
}, {
$set: {
blu: 43
}
});
}
这导致一次只需要一个文件存储在存储器中,这与例如已接受的答案相反,在文件处理开始之前,许多文件被吸进了存储器。在“大量收藏”的情况下(根据问题),这可能很重要。
如果文档很大,则可以通过使用projection进一步加以改进,以便仅从数据库中获取所需文档的那些字段。
- @ZachSmith:这是正确的,但速度很慢。使用 [bulkWrite](/sf/ask/1785550651/ 56333962#56333962)。 (3认同)
以前的答案都没有提到批处理更新。这使得它们非常慢——比使用bulkWrite的解决方案慢几十或几百倍。
假设您想将每个文档中的字段值加倍。以下是在固定内存消耗的情况下快速完成此操作的方法:
// Double the value of the 'foo' field in all documents
let bulkWrites = [];
const bulkDocumentsSize = 100; // how many documents to write at once
let i = 0;
db.collection.find({ ... }).forEach(doc => {
i++;
// Update the document...
doc.foo = doc.foo * 2;
// Add the update to an array of bulk operations to execute later
bulkWrites.push({
replaceOne: {
filter: { _id: doc._id },
replacement: doc,
},
});
// Update the documents and log progress every `bulkDocumentsSize` documents
if (i % bulkDocumentsSize === 0) {
db.collection.bulkWrite(bulkWrites);
bulkWrites = [];
print(`Updated ${i} documents`);
}
});
// Flush the last <100 bulk writes
db.collection.bulkWrite(bulkWrites);
var MongoClient = require('mongodb').MongoClient,
assert = require('assert');
MongoClient.connect('mongodb://localhost:27017/crunchbase', function(err, db) {
assert.equal(err, null);
console.log("Successfully connected to MongoDB.");
var query = {
"category_code": "biotech"
};
db.collection('companies').find(query).toArray(function(err, docs) {
assert.equal(err, null);
assert.notEqual(docs.length, 0);
docs.forEach(function(doc) {
console.log(doc.name + " is a " + doc.category_code + " company.");
});
db.close();
});
});
请注意,调用.toArray正在使应用程序获取整个数据集.
var MongoClient = require('mongodb').MongoClient,
assert = require('assert');
MongoClient.connect('mongodb://localhost:27017/crunchbase', function(err, db) {
assert.equal(err, null);
console.log("Successfully connected to MongoDB.");
var query = {
"category_code": "biotech"
};
var cursor = db.collection('companies').find(query);
function(doc) {
cursor.forEach(
console.log(doc.name + " is a " + doc.category_code + " company.");
},
function(err) {
assert.equal(err, null);
return db.close();
}
);
});
请注意,光标通过返回的find()分配给var cursor.使用这种方法,我们不是一次获取memort中的所有数据并一次使用数据,而是将数据流式传输到我们的应用程序.find()可以立即创建游标,因为在我们尝试使用它将提供的一些文档之前,它实际上并未向数据库发出请求.重点cursor是描述我们的查询.第二个参数cursor.forEach显示驱动程序耗尽或发生错误时要执行的操作.
在上面代码的初始版本中,它toArray()强制数据库调用.这意味着我们需要所有文件,并希望它们在一个文件中array.
此外,MongoDB以批处理格式返回数据.下图显示了游标(从应用程序)到的请求MongoDB
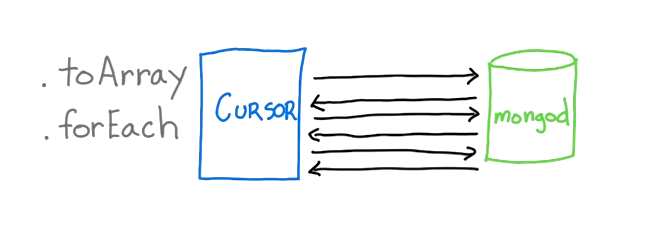
forEach是toArray因为我们可以处理文件,直到我们到达终点.对比toArray- 我们等待检索所有文档并构建整个数组.这意味着我们没有从驱动程序和数据库系统一起工作以将结果批量处理到您的应用程序的事实中获得任何好处.批处理旨在提供内存开销和执行时间方面的效率.如果可以在您的应用程序中使用它,请充分利用它.
- 好画:D (5认同)
- 游标在客户端处理数据时会导致额外的问题。由于系统的整个异步特性,数组更容易使用。 (2认同)
这是一个使用带有承诺的 Mongoose 游标异步的示例:
new Promise(function (resolve, reject) {
collection.find(query).cursor()
.on('data', function(doc) {
// ...
})
.on('error', reject)
.on('end', resolve);
})
.then(function () {
// ...
});
参考:
您现在可以使用(当然,在异步函数中):
for await (let doc of collection.find(query)) {
await updateDoc(doc);
}
// all done
它很好地序列化了所有更新。
| 归档时间: |
|
| 查看次数: |
70630 次 |
| 最近记录: |