正则表达式轮换命令
use*_*739 5 regex regex-alternation
我设置了一个复杂的正则表达式来从一页文本中提取数据.由于某种原因,交替的顺序不是我所期望的.一个简单的例子是:
((13th|(Executive |Residential)|((\w+) ){1,3})Floor)
简单地说,我试图得到一个楼层号码,一个已知的命名楼层,作为备份,我捕获1-3个不知名的单词后跟楼层,以防以后再查看(我实际上使用组名来识别这个但不想混淆这个问题)
问题是如果字符串是
on the 13th Floor
我不明白13th Floor我on the 13th Floor似乎表明它与第3次交替匹配.我原以为它会匹配13楼.我特意设置了这个(或者我认为),优先考虑匹配的类型,只有当其他人错过时,才会将模糊的匹配留给最后.当他们说Regex贪婪时,我猜他们并不是在开玩笑,但我不清楚如何将其设置为"贪婪"并按照我想要的方式行事.
嗯,一个自动机值得 1000 个单词:
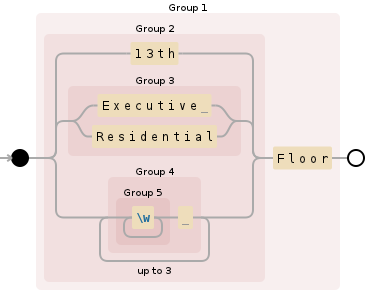
你的问题是你\w+在交替中使用了贪婪的子正则表达式。因为正如 @rigderunner 在他的评论中所述,NFA 正在匹配最长的最左边的子字符串,因此\w+将始终匹配 之前的任何内容Floor,无论它是一系列单词,或13th或Executive或Residential或其中的三个。括号不会改变交替的行为方式。
因此,它匹配但您不希望它匹配的最坏情况是:
xxxx yyyy zzz tttt Floor
正则表达式的问题在于,您期望做一些实际正则表达式无法做的事情:如果替代方案不起作用,您期望它匹配单词。因为常规语言无法跟踪状态,所以常规正则表达式无法表达这一点。
我实际上不确定使用某种前瞻是否可以帮助您在一个正则表达式中完成此操作,即使可以,您最终也会得到一个非常复杂、不可读甚至可能效率不高的正则表达式。
因此,您可能更喜欢使用两个正则表达式,并从第二个正则表达式获取组,以防第一个正则表达式失败:
((13th|Executive|Residential) +Floor)
如果没有匹配
((\w+ +){1:3}Floor)
注意:为了避免重复,请查看其他答案,其中我列出了有关正则表达式和 NFA 的有趣资源讲座。这将帮助您了解正则表达式的实际工作原理。