动物园管理员是卡夫卡必须的吗?
Paa*_*aji 96 partitioning producer-consumer broker apache-kafka apache-zookeeper
在Kafka中,我想只使用单个代理,单个主题和一个具有一个生产者和多个消费者的分区(每个消费者从代理获得自己的数据副本).鉴于此,我不希望使用Zookeeper的开销; 我不能只使用经纪人吗?为什么动物园管理员必须?
Joh*_*one 105
是的,运行Kafka需要Zookeeper.从Kafka入门文档:
第2步:启动服务器
Kafka使用zookeeper,因此如果您还没有动物园管理员服务器,则需要先启动它.您可以使用与kafka一起打包的便捷脚本来获取快速且脏的单节点zookeeper实例.
至于为什么,很久以前人们发现你需要有一些方法来协调分布式系统中的任务,状态管理,配置等.一些项目已经构建了自己的机制(想想MongoDB分片集群中的配置服务器,或Elasticsearch集群中的主节点).其他人选择利用Zookeeper作为通用的分布式过程协调系统.所以Kafka,Storm,HBase,SolrCloud只是命名一些都使用Zookeeper来帮助管理和协调.
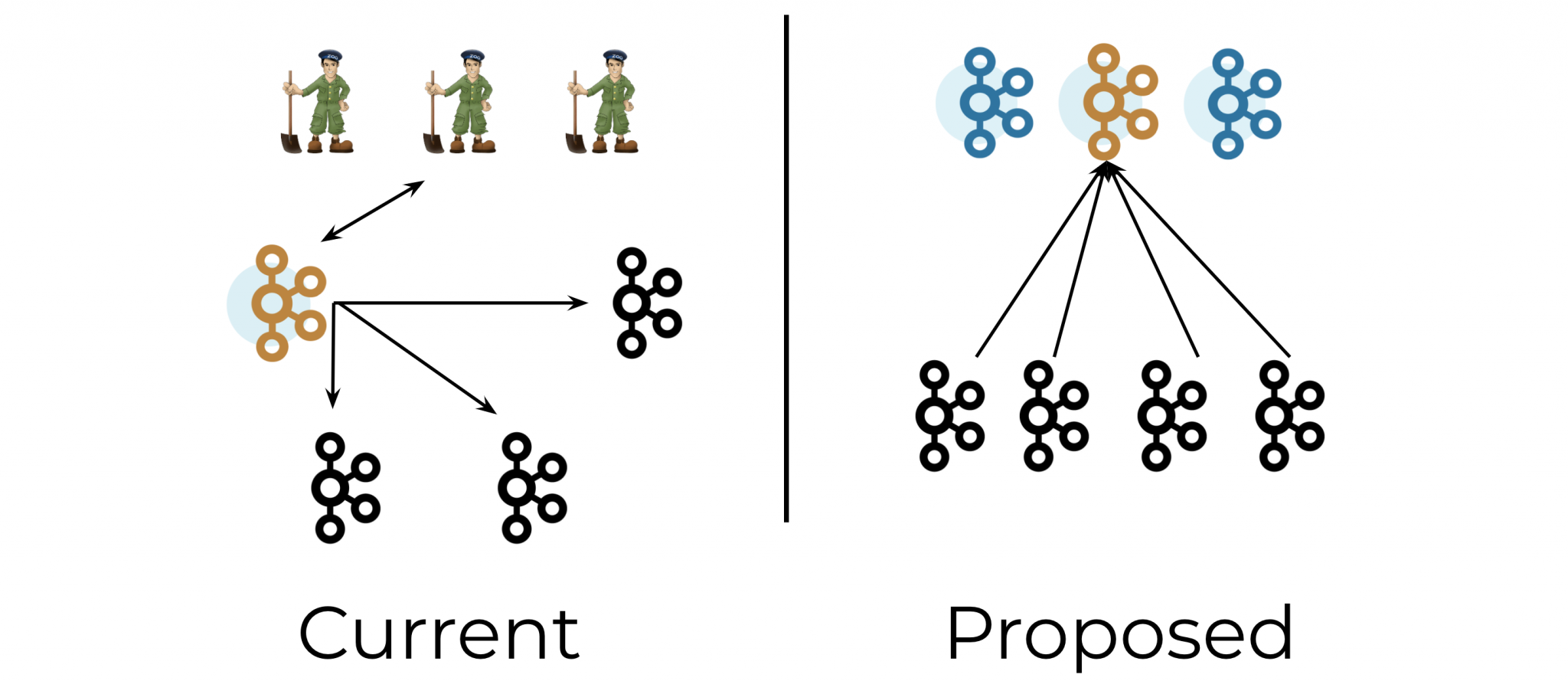
Kafka是一个分布式系统,用于使用Zookeeper.您没有使用Kafka的任何分布式功能这一事实并没有改变它的构建方式.无论如何,使用Zookeeper不应该有太多开销.更大的问题是为什么要使用这种特殊的设计模式--Kafka的单个代理实现错过了多代理集群的所有可靠性功能以及它的扩展能力.
- 实际上,kafka的设计方式即使在你使用单个代理**它仍然是**分布式模式,但复制因子为1 - 将没有快捷机制或特殊模式(这很好,实际上). (8认同)
- 卡夫卡0.8.1需要zk.而且我想知道,如果Kafka中没有抽象层与协调系统一起工作,那么如何为Kafka启用其他协调系统. (2认同)
- 重要更新 /sf/answers/4012969831/ (2认同)
Kev*_* Li 50
正如其他人所解释的那样,没有Zookeeper,Kafka(即使在最新版本中)也无法运行.
Kafka使用Zookeeper进行以下操作:
选择一个控制器.控制器是代理之一,负责维护所有分区的领导者/关注者关系.当节点关闭时,控制器会告诉其他副本成为分区负责人,以替换正在消失的节点上的分区负责人.Zookeeper用于选择控制器,确保只有一个控制器,如果它崩溃,则选择一个新控制器.
集群成员资格 - 哪些经纪人还活着并成为集群的一部分?这也是通过ZooKeeper管理的.
主题配置 - 存在哪些主题,每个分区有多少个分区,副本在哪里,谁是首选领导者,为每个主题设置了哪些配置覆盖
(0.9.0) - 配额 - 允许每个客户端读取和写入多少数据
(0.9.0) - ACL - 允许读取和写入哪个主题(旧的高级别消费者) - 存在哪些消费者组,谁是其成员以及每个组从每个分区获得的最新偏移量.
[来自https://www.quora.com/What-is-the-actual-role-of-ZooKeeper-in-Kafka/answer/Gwen-Shapira ]
关于您的场景,只有一个代理实例和一个具有多个消费者的生产者,您可以使用pusher创建一个渠道,并将事件推送到消费者可以订阅并传递这些事件的那个渠道. https://pusher.com/
- 你复制了https://www.quora.com/What-is-the-actual-role-of-ZooKeeper-in-Kafka/answer/Gwen-Shapira的答案 (5认同)
- 是否要将"最新版本"编辑为实际版本.让您的回应年龄更好. (3认同)
Isk*_*der 41
2021 年 2 月更新
对于最新版本(2.7.0)来说,运行 Kafka仍然需要ZooKeeper ,但在不久的将来ZooKeeper 将被一个自我管理的元数据 Quorum 取代。
请参阅已接受的KIP-500中的详细信息。
一、现状
Kafka 使用 ZooKeeper 来存储有关分区和代理的元数据,并选择一个代理作为 Kafka 控制器。
目前,正在消除对 ZooKeeper 的这种依赖(通过KIP-500)。
2. 去除利润
删除 Apache ZooKeeper 依赖项提供了三个不同的好处:
- 首先,它通过在 Kafka 本身中整合元数据来简化架构,而不是在 Kafka 和 ZooKeeper 之间拆分元数据。这提高了稳定性,简化了软件,并使监控、管理和支持 Kafka 变得更加容易。
- 其次,它提高了控制平面性能,使集群能够扩展到数百万个分区。
- 最后,它允许 Kafka 为整个系统拥有一个单一的安全模型,而不是一个用于 Kafka,一个用于 Zookeeper。
3. 路线图
ZooKeeper 预计在 2021 年被移除,并且有一些里程碑,这些里程碑体现在以下 KIP 中:
| KIP | Name | Status | Fix Version/s |
|:-------:|:--------------------------------------------------------:|:----------------:|---------------|
| KIP-455 | Create an Administrative API for Replica Reassignment | Accepted | 2.6.0 |
| KIP-497 | Add inter-broker API to alter ISR | Accepted | 2.7.0 |
| KIP-543 | Expand ConfigCommand's non-ZK functionality | Accepted | 2.6.0 |
| KIP-555 | Deprecate Direct ZK access in Kafka Administrative Tools | Accepted | None |
| KIP-589 | Add API to update Replica state in Controller | Accepted | 2.8.0 |
| KIP-590 | Redirect Zookeeper Mutation Protocols to The Controller | Accepted | 2.8.0 |
| KIP-595 | A Raft Protocol for the Metadata Quorum | Accepted | None |
| KIP-631 | The Quorum-based Kafka Controller | Under discussion | None |
KIP-500 引入了桥接版本的概念,可以与 KIP-500 之前和之后的 Kafka 版本共存。Bridge 版本很重要,因为它们可以实现对 ZooKeeper 后世界的零停机升级。
参考:
- KIP-500:用自我管理的元数据仲裁替换 ZooKeeper
- Apache Kafka 不需要 Keeper:移除 Apache ZooKeeper 依赖
- 为 KIP-500 准备您的客户端和工具:从 Apache Kafka 中移除 ZooKeeper
- 最后,Kafka 对 ZooKeeper 的依赖已在最新的 2.8.0 版本中删除,但它仍然是早期访问功能。 (2认同)
Kai*_*ner 18
重要更新-2019年8月:
ZooKeeper依赖关系将从Apache Kafka中删除。请参阅KIP-500中的高级讨论:用自我管理的元数据仲裁替换ZooKeeper。
这些工作将需要一些Kafka版本和其他KIP。Kafka控制器将接管当前的ZooKeeper任务。管制员将利用事件日志的好处,这是Kafka的核心概念。
新的Kafka架构的一些好处是更简单的架构,易于操作和更好的可伸缩性(例如,允许“无限分区”。
- 最后,Kafka 对 ZooKeeper 的依赖已在最新的 2.8.0 版本中删除,但它仍然是早期访问功能。 (3认同)
恕我直言,动物园管理员不是一个开销,但让你的生活更轻松.
它主要用于维护集群中不同节点之间的协调.Kafka最重要的事情之一是它使用zookeeper定期提交偏移量,以便在节点发生故障的情况下,它可以从先前提交的偏移量恢复(想象一下你自己处理所有这些).
Zookeeper还可以用于服务于许多其他目的,例如领导者检测,配置管理,同步,检测新节点何时加入或离开集群等.
未来的Kafka版本计划取消对zookeeper的依赖,但截至目前它已成为其中不可或缺的一部分.
以下是他们的常见问题解答页面中的几行:
一旦Zookeeper法定人数下降,经纪人可能会导致状态不佳,无法正常服务客户请求等.虽然当Zookeeper法定人数恢复时,卡夫卡经纪人应该能够自动恢复到正常状态,仍有一些极端情况他们不能,并且需要一个艰难的杀戮和恢复才能恢复正常.因此,建议密切监视您的zookeeper群集并对其进行配置,以使其具有高性能.
有关详细信息,请点击此处
- 动物园管理员很头疼.在HBase中.在卡夫卡.在风暴中.我在Kafka/ZK中发现长期存在的错误导致我的团队放弃它而转而使用RabbitMQ.安装HBase需要时间来处理ZK问题.但是你的答案与OP IS有关:ZK是必需的. (13认同)
- `恕我直言,动物园管理员不是一个开销,但让你的生活更容易. - >不是从一个系统的角度来看.Zk是一个落后的老java cruft.例如,它有一个很长的突出错误,因为它不遵守dns条目的ttl,因此它不会重新解析条目.窗外会出现服务器交换的可能性.我愿意为etcd愉快地交换它. (3认同)
- 确实存在 bug 和版本兼容性问题(至少对于 Kafka 和 ZK),但是 zookeeper 的主要目的是管理任何分布式系统所需的复杂任务。我同意管理和调整您的 zk 集群确实需要一些努力并且严重依赖在 zk 上可能不是一个明智的选择。可能这就是为什么 kafka 试图在以后的版本中减少 zk 依赖的原因。另一方面,我相信 RabitMQ 和 Kafka 有非常不同的设计理念,旨在解决不同的用例,但我认为这超出了本讨论的范围:) (2认同)
Zookeeper 是任何类型的分布式系统的集中管理系统。分布式系统是运行在不同节点/集群(可能在地理上很远的位置)上但作为一个系统运行的不同软件模块。Zookeeper 促进节点之间的通信,在节点之间共享配置,它跟踪哪个节点是领导者,哪个节点加入/离开等等。 Zookeeper 是保持分布式系统健全并保持一致性的人。Zookeeper 基本上是一个编排平台。
Kafka 是一个分布式系统。因此,它需要对其可能在地理上很远(或不在)的节点进行某种编排。
Apache Kafka v2.8.0让您可以提前访问KIP-500,它消除了 Zookeeper 对 Kafka 的依赖,这意味着它不再需要 Apache Zookeeper。
相反,Kafka 现在可以在Kafka Raft 元数据模式( KRaft mode) 下运行,从而启用内部 Raft 仲裁。当 Kafka 运行时,KRaft mode其元数据不再存储在 ZooKeeper 上,而是存储在控制器节点的内部仲裁上。这意味着您甚至不再需要运行 ZooKeeper。
但请注意,v2.8.0 目前处于早期访问阶段,您暂时不应在生产中使用无 Zookeeper 的 Kafka。
删除 ZooKeeper 依赖并用内部仲裁替换它的一些好处:
- 更高效,因为控制器不再需要在每次集群启动或进行控制器选举时与 ZooKeeper 通信来获取集群状态元数据
- 更具可扩展性,因为新的实现将能够支持更多主题和分区
KRaft mode - 更轻松的集群管理和配置,因为您不再需要管理两个不同的服务
- 单进程Kafka集群
有关更多详细信息,您可以阅读文章Kafka 不再需要 ZooKeeper
| 归档时间: |
|
| 查看次数: |
77595 次 |
| 最近记录: |