正则表达式拆分CSV
Cod*_*nja 38 regex csv quotes split asp-classic
我知道这个(或类似的)已被多次询问,但尝试了许多可能性,我无法找到一个100%正常的正则表达式.
我有一个CSV文件,我试图将它拆分成一个数组,但遇到两个问题:引用逗号和空元素.
CSV看起来像:
123,2.99,AMO024,Title,"Description, more info",,123987564
我试图使用的正则表达式是:
thisLine.split(/,(?=(?:[^\"]*\"[^\"]*\")*(?![^\"]*\"))/)
唯一的问题是在我的输出数组中,第5个元素是123987564,而不是空字符串.
Ro *_* Mi 47
描述
我认为简单地执行匹配并处理所有找到的匹配更容易,而不是使用拆分.
这个表达式将:
- 在逗号分隔上划分示例文本
- 将处理空值
- 将忽略双引号逗号,提供双引号不嵌套
- 修剪返回值的分隔逗号
- 修剪返回值的周围引号
正则表达式: (?:^|,)(?=[^"]|(")?)"?((?(1)[^"]*|[^,"]*))"?(?=,|$)

例
示范文本
123,2.99,AMO024,Title,"Description, more info",,123987564
ASP示例使用非java表达式
Set regEx = New RegExp
regEx.Global = True
regEx.IgnoreCase = True
regEx.MultiLine = True
sourcestring = "your source string"
regEx.Pattern = "(?:^|,)(?=[^""]|("")?)""?((?(1)[^""]*|[^,""]*))""?(?=,|$)"
Set Matches = regEx.Execute(sourcestring)
For z = 0 to Matches.Count-1
results = results & "Matches(" & z & ") = " & chr(34) & Server.HTMLEncode(Matches(z)) & chr(34) & chr(13)
For zz = 0 to Matches(z).SubMatches.Count-1
results = results & "Matches(" & z & ").SubMatches(" & zz & ") = " & chr(34) & Server.HTMLEncode(Matches(z).SubMatches(zz)) & chr(34) & chr(13)
next
results=Left(results,Len(results)-1) & chr(13)
next
Response.Write "<pre>" & results
使用非java表达式匹配
组0获取整个子字符串,其中包括逗号
组1获取引用(如果已使用)
组2获取的值不包括逗号
[0][0] = 123
[0][1] =
[0][2] = 123
[1][0] = ,2.99
[1][1] =
[1][2] = 2.99
[2][0] = ,AMO024
[2][1] =
[2][2] = AMO024
[3][0] = ,Title
[3][1] =
[3][2] = Title
[4][0] = ,"Description, more info"
[4][1] = "
[4][2] = Description, more info
[5][0] = ,
[5][1] =
[5][2] =
[6][0] = ,123987564
[6][1] =
[6][2] = 123987564
- 我正在使用一个网站生成这些图表http://www.debuggex.com/ (12认同)
- 您使用什么软件/网站来生成这些图表? (7认同)
- 这不会解析 [RFC 4180](https://tools.ietf.org/html/rfc4180) 中指定的 CSV 格式。例如`"""test"" test",`应该被解析为`"test" test,`,因为用2个`"`来表示一个`"`字符,但是没有检测到。 (2认同)
aww*_*smm 16
对此进行了一些研究并提出了这个解决方案:
(?:,|\n|^)("(?:(?:"")*[^"]*)*"|[^",\n]*|(?:\n|$))
该解决方案处理"漂亮"的CSV数据
"a","b",c,"d",e,f,,"g"
0: "a"
1: "b"
2: c
3: "d"
4: e
5: f
6:
7: "g"
和丑陋的事情一样
"""test"" one",test' two,"""test"" 'three'","""test 'four'"""
0: """test"" one"
1: test' two
2: """test"" 'three'"
3: """test 'four'"""
(?:,|\n|^) # all values must start at the beginning of the file,
# the end of the previous line, or at a comma
( # single capture group for ease of use; CSV can be either...
" # ...(A) a double quoted string, beginning with a double quote (")
(?: # character, containing any number (0+) of
(?:"")* # escaped double quotes (""), or
[^"]* # non-double quote characters
)* # in any order and any number of times
" # and ending with a double quote character
| # ...or (B) a non-quoted value
[^",\n]* # containing any number of characters which are not
# double quotes ("), commas (,), or newlines (\n)
| # ...or (C) a single newline or end-of-file character,
# used to capture empty values at the end of
(?:\n|$) # the file or at the ends of lines
)
- 很棒的解决方案!也适用于 .NET 的 Regex 类。 (2认同)
- 欣赏这个解决方案。PSA 如果您有一个空的第一列(例如`,foo,bar`),它将不会被捕获。一种解决方法是在解析之前在这样的行前加上空引号 `""`。 (2认同)
- 完美的。即使使用简单的示例,所有其他答案也会产生错误的结果,但这个答案适用于我的所有情况(不一致的外壳+值内的逗号)。 (2认同)
sco*_*art 10
几个月前我为一个项目创建了这个.
".+?"|[^"]+?(?=,)|(?<=,)[^"]+
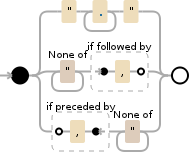
它在C#中工作,当我选择Python和PCRE时,Debuggex很高兴.JavaScript不承认这种形式继续通过?<= ....
对于您的值,它将创建匹配
123
,2.99
,AMO024
,Title
"Description, more info"
,
,123987564
请注意,引号中的任何内容都没有前导逗号,但空值用例需要尝试与前导逗号匹配.完成后,根据需要修剪值.
我使用RegexHero.Net来测试我的正则表达式.
- 尽管问题中的示例没有提到它,但完美的正则表达式算法还需要处理字段内的引号字符,例如:`single,"quoted","with ""quotes""",end`。你的还没有。 (2认同)
- "?" 在"+"指定非贪婪状态后,它将尽可能多地抓取下一个字符的第一个实例.例如,如果原始帖子有两个引用值,则不使用问号可以获取引号的第一个和最后一个实例之间的所有文本.双引号很难,我会看看我是否能找到解决方案. (2认同)
我也需要这个答案,但我找到了答案,虽然提供了信息,但有点难以理解和复制其他语言.这是我为CSV行中的单个列提出的最简单的表达式.我没有分裂.我正在构建一个正则表达式以匹配CSV中的列,因此我不会拆分该行:
("([^"]*)"|[^,]*)(,|$)
这与CSV行中的单个列匹配."([^"]*)"表达式的第一部分是匹配引用的条目,第二部分[^,]*是匹配未引用的条目.然后跟着一个,或一个结束$.
以及随附的debuggex来测试表达式.
https://www.debuggex.com/r/s4z_Qi2gZiyzpAhx
- 它可以在 JavaScript 中工作(这不是OP所要求的,但了解它会很有帮助)。 (3认同)
- 不处理转义的双引号 ("") (2认同)
我迟到了,但以下是我使用的正则表达式:
(?:,"|^")(""|[\w\W]*?)(?=",|"$)|(?:,(?!")|^(?!"))([^,]*?)(?=$|,)|(\r\n|\n)
此模式有三个捕获组:
- 引用单元格的内容
- 未加引号的单元格的内容
- 一条新线
此模式处理以下所有内容:
- 正常细胞内容没有任何特殊功能: 一,二,三
- 包含双引号的单元格("被转义为""): 无引号,"a""引用""的东西",结束
- 单元格包含换行符: 一个,两个\nthree,四个
- 具有内部引用的正常单元格内容: 一,二"三,四
- 单元格包含引号,后跟逗号: 一,"两","三","四",五
如果您正在使用具有命名组和lookbehinds的更强大的正则表达式,我更喜欢以下内容:
(?<quoted>(?<=,"|^")(?:""|[\w\W]*?)*(?=",|"$))|(?<normal>(?<=,(?!")|^(?!"))[^,]*?(?=(?<!")$|(?<!"),))|(?<eol>\r\n|\n)
编辑
(?:^"|,")(""|[\w\W]*?)(?=",|"$)|(?:^(?!")|,(?!"))([^,]*?)(?=$|,)|(\r\n|\n)
只要您不使用Javascript,这个稍微修改过的模式就会处理第一列为空的行.出于某种原因,Javascript将省略具有此模式的第二列.我无法正确处理这种边缘情况.
我个人尝试了许多 RegEx 表达式,但没有找到适合所有情况的完美表达式。
我认为正则表达式很难正确配置以正确匹配所有情况。尽管很少有人会不喜欢命名空间(我也是他们的一部分),但我提出了一些属于 .Net 框架的内容,并在所有情况下始终为我提供正确的结果(主要是很好地管理每个双引号情况):
Microsoft.VisualBasic.FileIO.TextFieldParser
在这里找到:StackOverflow
用法示例:
TextReader textReader = new StringReader(simBaseCaseScenario.GetSimStudy().Study.FilesToDeleteWhenComplete);
Microsoft.VisualBasic.FileIO.TextFieldParser textFieldParser = new TextFieldParser(textReader);
textFieldParser.SetDelimiters(new string[] { ";" });
string[] fields = textFieldParser.ReadFields();
foreach (string path in fields)
{
...
希望它能有所帮助。
| 归档时间: |
|
| 查看次数: |
79376 次 |
| 最近记录: |