Tar*_*ila 10 c++ memory memory-management
在C++中,假设没有优化,那么以下两个程序最终会使用相同的内存分配机器代码吗?
int main()
{
int i;
int *p;
}
int main()
{
int *p = new int;
delete p;
}
San*_*nto 24
为了更好地理解正在发生的事情,让我们假设我们只有一个非常原始的操作系统在一个16位处理器上运行,一次只能运行一个进程.这就是说:一次只能运行一个程序.此外,让我们假装所有中断都被禁用.
我们的处理器中有一个称为堆栈的构造.堆栈是强加在物理内存上的逻辑构造.假设我们的RAM存在于地址E000到FFFF中.这意味着我们正在运行的程序可以按照我们想要的方式使用这个内存.让我们假设我们的操作系统说E000到EFFF是堆栈,而F000到FFFF是堆.
堆栈由硬件和机器指令维护.我们没有太多需要做的来维护它.我们(或我们的操作系统)需要做的就是确保为堆栈的开始设置正确的地址.堆栈指针是物理实体,驻留在硬件(处理器)中并由处理器指令管理.在这种情况下,我们的堆栈指针将设置为EFFF(假设堆栈增长了BACKWARDS,这很常见, - ).使用像C这样的编译语言,当你调用一个函数时,它会将你传入的任何参数推送到堆栈上的函数中.每个参数都有一定的大小.int通常是16位或32位,char通常是8位,等等.让我们假装在我们的系统上,int和int*是16位.对于每个参数,堆栈指针由sizeof(参数)为DECREMENTED( - ),并且参数被复制到堆栈中.然后,您在范围中声明的任何变量都以相同的方式被压入堆栈,但它们的值未初始化.
让我们重新考虑两个与你的两个例子类似的例子.
int hello(int eeep)
{
int i;
int *p;
}
在我们的16位系统上发生的事情如下:1)将eeep推入堆栈.这意味着我们将堆栈指针递减到EFFD(因为sizeof(int)是2)然后实际复制eeep以解决EFFE(堆栈指针的当前值减去1,因为我们的堆栈指针指向可用的第一个点分配后).有时会有一些指令可以一举做到(假设您正在复制适合寄存器的数据.否则,您必须手动将数据类型的每个元素复制到堆栈中的适当位置 - 顺序! ).
2)为我创造空间.这可能意味着只是将堆栈指针递减到EFFB.
3)为p创建空间.这可能意味着只是将堆栈指针递减到EFF9.
然后我们的程序运行,记住我们的变量存在的位置(eeep从EFFE开始,我在EFFC,而在EFFA开始).要记住的重要一点是,即使堆栈计数BACKWARDS,变量仍然运行FORWARDS(这实际上取决于字节序,但重点是&eeep == EFFE,而不是EFFF).
当函数关闭时,我们简单地将堆栈指针递增(++)6,(因为3个大小为2的"对象"而不是c ++类型已经被压入堆栈.
现在,你的第二个场景要难以解释,因为实现它的方法太多了,几乎不可能在互联网上解释.
int hello(int eeep)
{
int *p = malloc(sizeof(int));//C's pseudo-equivalent of new
free(p);//C's pseudo-equivalent of delete
}
仍然按照前面的示例推送和分配堆栈中的eeep和p.但是,在这种情况下,我们将p初始化为函数调用的结果.什么的malloc(或新的,但新的做更多在C++中,它调用适当的时候构造函数,和一切.)所做的是它进入这个黑盒子称为堆和获得可用内存的地址.我们的操作系统将为我们管理堆,但是我们必须让它知道我们何时需要内存以及何时完成它.
在这个例子中,当我们调用malloc()时,操作系统将返回一个2字节的块(我们系统上的sizeof(int)为2),给出这些字节的起始地址.假设第一个电话给了我们地址F000.操作系统随后跟踪当前正在使用的地址F000和F001.当我们调用free(p)时,操作系统会找到p指向的内存块,并将2个字节标记为未使用(因为sizeof(star p)为2).相反,如果我们分配更多内存,地址F002可能会作为新内存的起始块返回.请注意,malloc()本身就是一个函数.当p被推入堆栈以进行malloc()的调用时,p会在第一个打开的地址处再次复制到堆栈上,堆栈上有足够的空间来适应p的大小(可能是EFFB,因为我们只推了2个这次大小为2的堆栈上的东西,sizeof(p)是2),堆栈指针再次递减到EFF9,malloc()将把它的局部变量放在堆栈中,从这个位置开始.当malloc完成时,它会将所有项目从堆栈中弹出,并将堆栈指针设置为调用它之前的内容.malloc()(一个void星)的返回值可能会放在某个寄存器(通常是许多系统上的累加器)中供我们使用.
在实现中,两个示例真的不是这么简单.当您分配堆栈内存时,对于新的函数调用,您必须确保保存状态(保存所有寄存器),以便新函数不会永久擦除值.这通常也会将它们推到堆叠上.同样,您通常会保存程序计数器寄存器,以便在子程序返回后返回正确的位置.内存管理器会耗尽自己的内存,以"记住"已经发出的内存和没有内存的内存.虚拟内存和内存分段使这个过程变得更加复杂,内存管理算法必须不断地移动块(并保护它们)以防止内存碎片(它自己的整个主题),这与虚拟内存相关联同样.与第一个例子相比,第二个例子确实是一大堆蠕虫.此外,运行多个进程会使所有这些变得更加复杂,因为每个进程都有自己的堆栈,并且堆可以被多个进程访问(这意味着它必须保护自己).此外,每个处理器架构都不同.一些架构希望您将堆栈指针设置为堆栈上的第一个空闲地址,其他架构将指望您将其指向第一个非空闲点.
我希望这有帮助.请告诉我.
请注意,上述所有示例都适用于过度简化的虚构机器.在真正的硬件上,这会变得更加毛茸茸.
编辑:星号未显示.我用"星"这个词取而代之
对于它的价值,如果我们在示例中使用(大部分)相同的代码,分别用"example1"和"example2"替换"hello",我们在wndows上获得以下的intel组件输出.
.file "test1.c"
.text
.globl _example1
.def _example1; .scl 2; .type 32; .endef
_example1:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
leave
ret
.globl _example2
.def _example2; .scl 2; .type 32; .endef
_example2:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $4, (%esp)
call _malloc
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
movl %eax, (%esp)
call _free
leave
ret
.def _free; .scl 3; .type 32; .endef
.def _malloc; .scl 3; .type 32; .endef
sha*_*oth 18
不,没有优化......
int main()
{
int i;
int *p;
}
什么也没做 - 只是调整堆栈指针的几条指令,但是
int main()
{
int *p = new int;
delete p;
}
在堆上分配一块内存然后释放它,这是一大堆工作(我在这里很认真 - 堆分配不是一个简单的操作).
int i;
int *p;
^在堆栈上分配一个整数和一个整数指针
int *p = new int;
delete p;
^在堆栈上分配一个整数指针,在堆上分配整数大小的块
编辑:
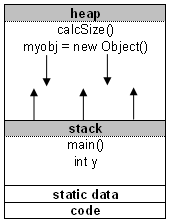
堆栈段和堆段之间的差异
alt text http://www.maxi-pedia.com/web_files/images/HeapAndStack.png
void another_function(){
int var1_in_other_function; /* Stack- main-y-sr-another_function-var1_in_other_function */
int var2_in_other_function;/* Stack- main-y-sr-another_function-var1_in_other_function-var2_in_other_function */
}
int main() { /* Stack- main */
int y; /* Stack- main-y */
char str; /* Stack- main-y-sr */
another_function(); /*Stack- main-y-sr-another_function*/
return 1 ; /* Stack- main-y-sr */ //stack will be empty after this statement
}
每当任何程序开始执行时,它将所有变量存储在称为Stack segment的特殊memoy内存位置.例如,在C/C++的情况下,第一个被调用的函数是main.所以它将首先放在堆栈上.main中的任何变量都将在程序执行时置于堆栈中.现在main是第一个被调用的函数,它将是最后一个返回任何值的函数(或者将从堆栈中弹出).
现在,当您使用new另一个特殊内存位置动态分配内存时,使用称为Heap segment.即使堆指针上存在实际数据也位于堆栈上.
{kind=link}