5 algorithm levenshtein-distance
我有一个给出'n'字样的字典,并且有'm'查询要回复.我想在字典中输出编辑距离为1或2的单词数.我想优化结果集,因为n和m大约是3000.
编辑从以下答案中添加:
我会尝试用不同的方式来表达它.
最初有'n'个单词作为一组字典单词给出.接下来给出的'm'单词是查询单词,对于每个查询单词,我需要查找单词是否已经存在于Dictionary(编辑距离'0')中,或者字典中单词的总计数是否在编辑距离1或者2来自字典的单词.
我希望问题现在是明确的.
好吧,如果时间复杂度为(m*n)n则超时.DP编辑距离算法的天真使用超时.甚至计算2k + 1次的对角元素,其中k是阈值,在这里k = 3.
你想使用两个单词之间的Levenshtein距离,但我想你知道,因为那是问题的标签所说的.
您必须遍历List(假设)并将列表中的每个单词与您正在执行的当前查询进行比较.您可以构建一个BK树来限制您的搜索空间,但如果您只有大约3000个单词,那听起来就像是一种矫枉过正.
var upperLimit = 2;
var allWords = GetAllWords();
var matchingWords = allWords
.Where(word => Levenshtein(query, word) <= upperLimit)
.ToList();
编辑原始问题后添加
查找距离= 0的情况很容易包含查询,如果您有不区分大小写的字典.距离<= 2的情况需要搜索空间的完整扫描,每个查询字的3000次比较.假设相同数量的查询单词将导致900万次比较.
你提到它超时了,所以我假设你配置了一个超时?您的速度可能是由于Levenshtein计算的执行不力或缓慢造成的吗?
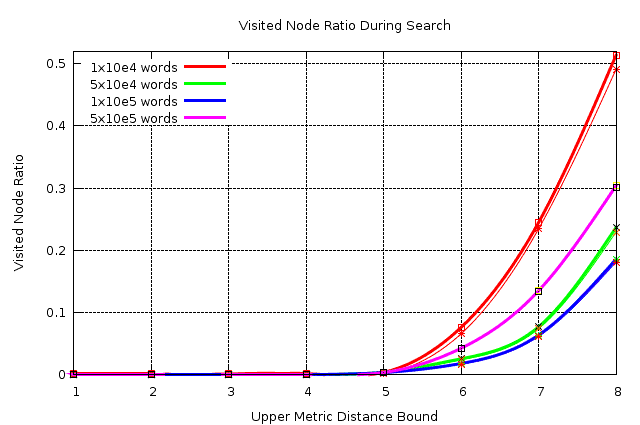
使用具有不同输入量的bk树显示访问搜索空间的 图表http://www.students.itu.edu.tr/~yazicivo/bk-tree-report.png上图是从CLiki中窃取的:bk-tree
如图所示,使用编辑距离<= 2的bk-tree只能访问大约1%的搜索空间,但这假设你有一个非常大的输入数据,在他们的情况下高达五十万字.在你的情况下,我会假设相似的数字,但即使存储在List/Dictionary中,如此少量的输入也不会造成太大麻烦.
{kind=link}