问题列表 - 第6610页
在C#中比较数组
我试图将两个数组相互比较.我试过这段代码并得到以下错误.
static bool ArraysEqual(Array a1, Array a2)
{
if (a1 == a2)
return true;
if (a1 == null || a2 == null)
return false;
if (a1.Length != a2.Length)
return false;
IList list1 = a1, list2 = a2; //error CS0305: Using the generic type 'System.Collections.Generic.IList<T>' requires '1' type arguments
for (int i = 0; i < a1.Length; i++)
{
if (!Object.Equals(list1[i], list2[i])) //error CS0021: Cannot apply indexing with [] to an expression of type 'IList'(x2)
return false;
}
return true;
} …推荐指数
解决办法
查看次数
推荐指数
解决办法
查看次数
合理的日语支持是什么最小的unicode字符集?
我有一个需要移植给日本观众的移动应用程序.部分应用程序是一个自定义字体文件,需要从仅包含latin-1字符扩展到也包含日语字符.我意识到这将使它相当大,但这不是今天的问题.
请注意,我无法控制此应用程序要显示的文本,因此它需要能够支持足以显示用户生成的内容.
以下是我认为最大的unicode范围集合,可以涵盖所需的任何内容.
Compatability U+3300 - U+33FF
Compatability forms U+FE30 - U+FE4F
Compatability ideographs U+F900 - U+FAFF
Compatability ideographs supplement U+2F800 - U+2FA1F
Radicals supplement U+2E80 - U+2EFF
Strokes U+31C0 - U+31EF
Symbols and punctuation U+3000 - U+303F
Unified Ideographs U+4E00 - U+9FBB
Unified Ideographs ext. A U+3400 - U+4DB5
Unified Ideographs ext. B U+20000 - U+2A6D6
Enclosed letters and months U+3200 - U+32FF
Hiragana U+3040 - U+309F
Kanbun U+3190 - U+319F
Katakana U+30A0 - U+30FF
Katakana phonetic U+31F0 - …推荐指数
解决办法
查看次数
为什么"Namespace Provider"属性不会保存在给定子目录的项目文件中?
VS2008项目中的子目录主要用于在磁盘上物理表示项目的命名空间结构.每个文件夹都有一个名为"Namespace Provider"的布尔属性,当设置为True时,ReSharper会验证给定类的物理位置是否与逻辑命名空间位置相对应.
有时我不希望将文件夹用作命名空间提供程序,因此我将此属性设置为False,并且ReSharper不执行检查.
问题
此设置不会保存在项目文件中,因此下次打开解决方案时将恢复为默认值True.这不是什么大不了的事,但ReSharper确实会给你很多关于不正确命名空间的警告.
为什么财产价值没有得到保存?
版本...
带VS2008 SP1的ReSharper 4.0
resharper code-analysis namespaces visual-studio-2008 visual-studio
推荐指数
解决办法
查看次数
如何在同一解决方案中引用C++/CLi项目中的C#项目
我在解决方案中有两个项目,一个是C#库,另一个是C++/CLI库.
我在C++/CLI项目中使用引用菜单添加了一个引用到c#库.然后我添加了
#using <assembly.name.dll>
并尝试引用程序集
using namespace namspace.subnamespace;
但我得到无法找到assembly.name.dll的错误.我已经尝试将案例和所有小写字母匹配为程序集名称,但无济于事.令人惊讶的是,互联网上没有任何关于如何引用自己创建的程序集的参考.
这样做是正确的,如果我做得对,我应该采取什么方法来诊断这一点.
推荐指数
解决办法
查看次数
SQL Server中唯一标识符ID列上的群集主键
如果表上的ID列是唯一标识符(Guid),那么在ID列上创建聚簇主键是否有任何意义?
鉴于它们是全球唯一的,排序将如何运作?
推荐指数
解决办法
查看次数
F#(和.NET)中的浮点精度
在" F#for Scientists "中,Jon Harrop说:
粗略地说,int类型的值近似于min-int和max-int之间的实数,并且绝对误差为+ - 1/2,而float类型的值具有近似恒定的相对误差,这是一个百分比的一小部分.
现在,这是什么意思?Int类型不准确?
为什么C#为(1 - 0.9)返回0.1但F#返回0.099999999999978?C#更准确,适合科学计算吗?
我们应该使用十进制值而不是double/float来进行科学计算吗?
推荐指数
解决办法
查看次数
C#拆分合并?
我喜欢我能做的 string [] stringArray = sz.split('.');
但有没有办法将它们合并在一起? (stringArray.Merge(".");)
推荐指数
解决办法
查看次数
推荐指数
解决办法
查看次数
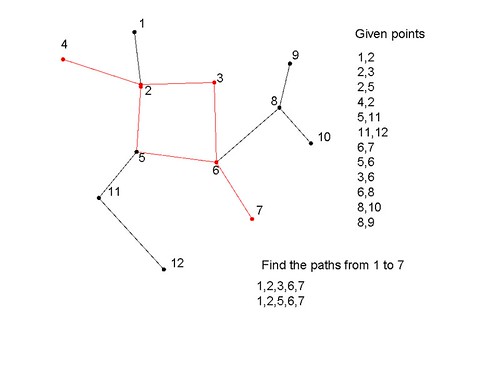
找到两个给定节点之间的路径?
假设我以下面的方式连接节点,我如何得出给定点之间存在的路径数量和路径详细信息?
1,2 //node 1 and 2 are connected
2,3
2,5
4,2
5,11
11,12
6,7
5,6
3,6
6,8
8,10
8,9
找到1到7的路径:
答案:找到2条路径,它们是
1,2,3,6,7
1,2,5,6,7
在这里找到的实现很好,我将使用相同的
这是python中上面链接的片段
# a sample graph
graph = {'A': ['B', 'C','E'],
'B': ['A','C', 'D'],
'C': ['D'],
'D': ['C'],
'E': ['F','D'],
'F': ['C']}
class MyQUEUE: # just an implementation of a queue
def __init__(self):
self.holder = []
def enqueue(self,val):
self.holder.append(val)
def dequeue(self):
val = None
try:
val = self.holder[0]
if len(self.holder) == 1:
self.holder = [] …推荐指数
解决办法
查看次数
标签 统计
c# ×5
algorithm ×1
arrays ×1
c++-cli ×1
f# ×1
fonts ×1
graph-theory ×1
namespaces ×1
path ×1
primary-key ×1
pseudocode ×1
reference ×1
resharper ×1
sql-server ×1
string ×1
text ×1
unicode ×1
winapi ×1