问题列表 - 第18456页
PHP中有哪些不同的请求和响应范围?
我从我古老的Java时代稍微记得,有一个RequestScope对象和一个Response对象.RequestScope包含从浏览器发送的POST头和GET参数.好吧,几年前,可能是不准确的.
PHP环境中有哪些请求和响应范围?好吧,我认为有一个$ _GET和$ _POST(对不起,如果错了,我只是几天新的PHP).那是唯一的吗?输出在哪里?
推荐指数
解决办法
查看次数
CPU寄存器和高速缓存一致性
当涉及到MESI等缓存一致性协议时,CPU寄存器和CPU缓存之间的关系是什么?如果某个值存储在CPU的缓存中,并且也存储在寄存器中,那么如果缓存行被标记为"脏"会发生什么?根据我的理解,即使缓存更新(由于MESI),寄存器也不会更新它的值.
亨赫这段代码:
static void Main()
{
bool complete = false;
var t = new Thread (() =>
{
bool toggle = false;
while (!complete) toggle = !toggle;
});
t.Start();
Thread.Sleep (1000);
complete = true;
t.Join(); // Blocks indefinitely
}
(假设编译器没有优化循环外"完成"的加载)据
我所知,第二个线程看不到"完成"的更新,因为它的值保存在寄存器内(CPU 2的缓存是然而,更新).
是否设置内存屏障力来"刷新"所有寄存器?寄存器与缓存的关系是什么?那些寄存器和内存障碍呢?
推荐指数
解决办法
查看次数
为什么RedirectStandardOutput没有必要的ANSI代码?
确定这里是我做了测试一个简单的控制台应用程序RedirectStandardOutput的Process.StartInfo.
foreach (c In [Enum].GetValues(GetType(ConsoleColor))
{
Console.ForegroundColor = c
Console.WriteLine("Test")
}
以下是申请结果.
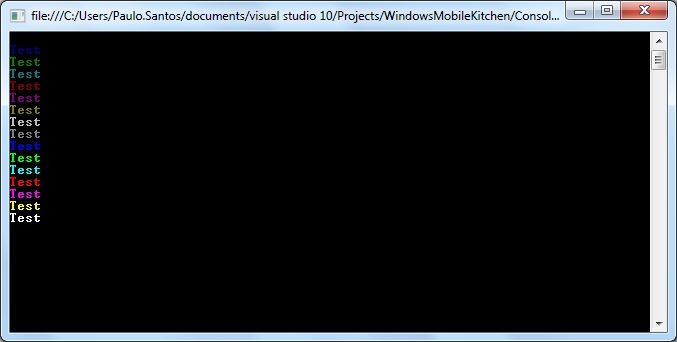
因此我们可以看到控制台上的颜色很漂亮.
但是,当我读到StandardOutput.BaseStream没有颜色信息,没有ANSI代码,没有任何东西.
如何捕获重定向流上的颜色信息?
推荐指数
解决办法
查看次数
如何衡量锁争用?
我正在阅读http://lse.sourceforge.net/locking/dcache/dcache_lock.html,其中测量每个函数的自旋锁时间:
SPINLOCKS HOLD WAIT
UTIL CON MEAN( MAX ) MEAN( MAX )(% CPU) TOTAL NOWAIT SPIN RJECT NAME
5.3% 16.5% 0.6us(2787us) 5.0us(3094us)(0.89%) 15069563 83.5% 16.5% 0% dcache_lock
0.01% 10.9% 0.2us( 7.5us) 5.3us( 116us)(0.00%) 119448 89.1% 10.9% 0% d_alloc+0x128
0.04% 14.2% 0.3us( 42us) 6.3us( 925us)(0.02%) 233290 85.8% 14.2% 0% d_delete+0x10
0.00% 3.5% 0.2us( 3.1us) 5.6us( 41us)(0.00%) 5050 96.5% 3.5% 0% d_delete+0x94
我想知道这些统计数据来自哪里.我试过oprofile,但似乎oprofile无法测量特定锁的锁定和等待时间.而valgrind的drd会使应用程序放慢太多,这会使结果不准确并且消耗太多时间.mutrace似乎很好,但正如名称所指出的,我担心它只能追踪互斥排除.
那么有没有其他工具,或者如何使用我上面提到的工具来获取锁争用统计信息?
感谢您的回复.
推荐指数
解决办法
查看次数
基于DFA的Java正则表达式引擎与Capture
是否有任何(免费)Java正则表达式引擎,可以将正则表达式编译为DFA,并在匹配DFA时进行组捕获?
我找到了dk.brics.automaton和jrexx,它们都编译成DFA,但似乎都无法进行群组捕获.虽然我发现的其他引擎似乎编译为NFA.
推荐指数
解决办法
查看次数
在Java-"无法导入默认包的静态成员" - 有人可以解释这个语句吗?
在Java-"无法导入默认包的静态成员" - 有人可以解释这个语句吗?如果它有一个例子会更好.我不确定它是否有一个非常简单的答案,但后来我试图理解,但无法弄明白.
推荐指数
解决办法
查看次数
共享内存,MPI和排队系统
我的unix/windows C++应用程序已经使用MPI进行了并行化:作业被分割为N cpus,并且每个块都是并行执行,非常高效,非常好的速度缩放,工作正确完成.
但是在每个过程中都会重复一些数据,并且由于技术原因,这些数据不能轻易地通过MPI(...)进行分割.例如:
- 5 Gb的静态数据,为每个进程加载完全相同的东西
- 可以在MPI中分发的4 Gb数据,使用的CPU越多,每个CPU的RAM越小.
在4 CPU工作中,这意味着至少有20Gb的RAM负载,大部分内存"浪费",这很糟糕.
我正在考虑使用共享内存来减少总体负载,每台计算机只会加载一次"静态"块.
所以,主要问题是:
是否有任何标准的MPI方式在节点上共享内存? 某种现成的+免费图书馆?
- 如果没有,我将使用
boost.interprocess和使用MPI调用来分发本地共享内存标识符. - 共享内存将由每个节点上的"本地主机"读取,并以只读方式共享.不需要任何类型的信号量/同步,因为它不会改变.
- 如果没有,我将使用
任何性能损失或特别问题要警惕?
- (不会有任何"字符串"或过于奇怪的数据结构,一切都可以归结为数组和结构指针)
该作业将在PBS(或SGE)排队系统中执行,如果进程不干净退出,我想知道这些是否会清理特定于节点的共享内存.
推荐指数
解决办法
查看次数
检查Windows版本
如果计算机上安装的Windows版本是Windows Vista及更高版本(Windows 7),我如何签入C++?
推荐指数
解决办法
查看次数
从枚举中获取整数值
我正在制作一个基本的战舰游戏,以帮助我的C#技能.现在我对枚举有点麻烦.我有:
enum game : int
{
a=1,
b=2,
c=3,
}
我希望播放器传递输入"C",一些代码返回整数3.我如何设置它以获取字符串var(string pick;)并使用此枚举将其转换为正确的int?我正在阅读的这本书有点令人困惑
推荐指数
解决办法
查看次数
俄罗斯方块:类的布局
我写了一个工作的俄罗斯方块克隆,但它有一个非常凌乱的布局.我可以获得有关如何重构我的类以使我的编码更好的反馈.我专注于使我的代码尽可能通用,试图使它更像是仅使用块的游戏引擎.
每个块都是在游戏中单独创建的.我的游戏有2个BlockLists(链表):StaticBlocks和Tetroid.StaticBlocks显然是所有非移动块的列表,而tetroid是当前tetroid的4个块.
主要是世界被创造.
首先创建一个新的tetroid(列表Tetroid中的4个块)(NewTetroid)
通过(***碰撞)函数检测碰撞,通过使用(If*****)函数比较每个Tetroid和所有StaticBlock.
当tetroid停止(击中底部/块)时,它被复制(CopyTetroid)到StaticBlocks并且Tetroid变为空,然后通过用(SearchY)搜索StaticBlocks来测试完整的行,销毁/删除块等.
创建了一个新的tetroid.
(TranslateTetroid)和(RotateTetroid)逐个对Tetroid列表中的每个块执行操作(我认为这是不好的做法).
(DrawBlockList)只是遍历一个列表,为每个块运行Draw()函数.
通过在调用(NewTetroid)时相对于Tetroid中的第一个块设置旋转轴来控制旋转.我的每个程序段的旋转功能(旋转)使其围绕轴旋转,使用输入+ -1进行左/右旋转.RotationModes和States用于以2种或4种不同方式旋转的块,定义它们当前处于什么状态,以及它们是应该向左还是向右旋转.我不满意这些在"世界"中的定义,但我不知道在哪里放置它们,同时仍然保持我的(旋转)功能对每个块都是通用的.
我的课程如下
class World
{
public:
/* Constructor/Destructor */
World();
~World();
/* Blocks Operations */
void AppendBlock(int, int, BlockList&);
void RemoveBlock(Block*, BlockList&);;
/* Tetroid Operations */
void NewTetroid(int, int, int, BlockList&);
void TranslateTetroid(int, int, BlockList&);
void RotateTetroid(int, BlockList&);
void CopyTetroid(BlockList&, BlockList&);
/* Draw */
void DrawBlockList(BlockList&);
void DrawWalls();
/* Collisions */
bool TranslateCollide(int, int, BlockList&, BlockList&);
bool RotateCollide(int, BlockList&, BlockList&);
bool OverlapCollide(BlockList&, BlockList&); // For end …推荐指数
解决办法
查看次数