我有一台 HP ProLiant Microserver Gen9。它具有 HP ILO 版本 4,但基于 Java 的远程控制台不能可靠地工作,而且我无法在 ILO 免费版本的 POST 屏幕后使用它(要求我购买 ILO 高级许可证)。所以我想改用串行控制台来登录服务器。
我必须在 Ubuntu 系统上做什么才能通过服务器的 ILO 网络端口在串行控制台中获取引导过程的所有阶段(POST、BIOS 配置、GRUB 输出、最终登录提示)?我如何连接到它?
想象一下,您不小心使用了mount --bind隐藏,/bin以便umount(以及大多数其他二进制文件)不再可见。
你将如何摆脱这种情况?
除了硬重启还有什么办法吗?
我有两个硬盘分区,我使用 将它们组合成一个 RAID1 mdadm,并在生成的设备上创建了一个 ext4 文件系统。
当我mdadm --zero-superblock将这两个分区,并重新创建 RAID 时,原始的 ext4 元数据就被神奇地保留了下来。
这是为什么?
我怎么知道mdadm给我一个真正新的、未初始化的 MD?
我如何创建 RAID1 和文件系统:
ls /dev/sdc2 # partition 1
ls /dev/sdd2 # partition 2
mdadm --create --run --verbose /dev/md1 --level=1 --raid-devices=2 /dev/sdc2 /dev/sdd2
mkfs.ext4 -L mylabel /dev/md1
擦除 RAID1:
mdadm --stop /dev/md1
mdadm --zero-superblock /dev/sdc2
mdadm --zero-superblock /dev/sdd2
重新创建 RAID1:
mdadm --create --run --verbose /dev/md1 --level=1 --raid-devices=2 /dev/sdc2 /dev/sdd2
显示设备信息(注意wipefs没有-a标志不会擦除任何东西,只是显示信息):
# wipefs /dev/md1
offset type
---------------------------------------------------------------- …我有 2 台服务器位于运行 Ubuntu 16.04 的机架中,它们之间有 1 米长的以太网电缆,都具有标准的英特尔以太网适配器。
两者ping之间大约是300 us(微秒)。
这是我在大多数千兆以太网设置中看到的标准延迟。
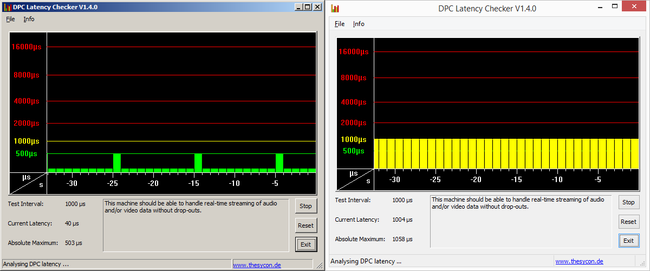
但是与理论限制相比,这种延迟似乎仍然很高;为什么?我读过 1 GbE 可以实现 40 us 的延迟。
这是我可以预期的最小延迟,还是我可以执行软件调整来减少这种延迟?瓶颈是什么?是Linux吗?在这个适用于 Windows的游戏玩家网站上,屏幕截图中的工具在大多数情况下似乎表明延迟为 40 us,但这对我的 Linux 服务器并没有多大帮助。
(如何)我可以让我的ping40 个我们?
编辑:在寻找的截图再次,它可能是我们出的40是不实际的往返时间,但它实际上是Windows内核中的特定的延迟,因此40我们可能只是部分的总往返时间,这可能更高,未列出。这也符合这里的答案。
(我最初是在超级用户处问这个问题的;此时我不清楚 ServerFault 是一个更合适的社区来询问网络性能问题,而且我在那里没有足够的声誉来提出这个问题,所以我重新提出在这里。我也将硬件切换到服务器硬件。)
ethernet ×1
hp-proliant ×1
ilo ×1
latency ×1
linux ×1
mdadm ×1
mount ×1
networking ×1
performance ×1
ping ×1
raid ×1
serial ×1
ubuntu-16.04 ×1
{kind=link}