小编Pet*_*yer的帖子
调整 Linux 磁盘缓存行为以获得最大吞吐量
我在这里遇到了最大吞吐量问题,需要一些关于如何调整旋钮的建议。我们正在运行一个 10Gbit 的文件服务器来进行备份分发。这是一个 LSI MegaRAID 控制器上的两个磁盘 S-ATA2 设置。服务器还获得了 24gig 的内存。
我们需要以最大吞吐量镜像上次上传的备份。
用于“热”备份的 RAID0 为我们提供了大约 260 MB/秒的写入速度和 275 MB/秒的读取速度。经过测试的 20GB 大小的 tmpfs 为我们提供了大约 1GB/秒的速度。这种吞吐量正是我们所需要的。
现在如何调整 Linux 的虚拟内存子系统以在内存中尽可能长时间地缓存最后上传的文件而不将它们写到磁盘(或者甚至更好:写入磁盘并将它们保存在内存中)?
我设置了以下 sysctls,但它们没有给我们预期的吞吐量:
# VM pressure fixes
vm.swappiness = 20
vm.dirty_ratio = 70
vm.dirty_background_ratio = 30
vm.dirty_writeback_centisecs = 60000
这理论上应该给我们 16GB 的缓存 I/O 并等待几分钟直到它写入磁盘。仍然当我对服务器进行基准测试时,我发现对写入没有影响,吞吐量没有增加。
需要帮助或建议。
12
推荐指数
推荐指数
1
解决办法
解决办法
1万
查看次数
查看次数
需要 Linux WAN 故障转移简单解决方案
我正在努力想出一个聪明而简单的 WAN 故障转移解决方案。这适用于具有两个不同外部 IP 的 SOHO 安装。只需要出站连接故障转移。
- 提供商 1:电缆
- 提供商 2:无线
防火墙是 Debian GNU/Linux,所以解决方案应该使用 Linux 并且是基于软件的。
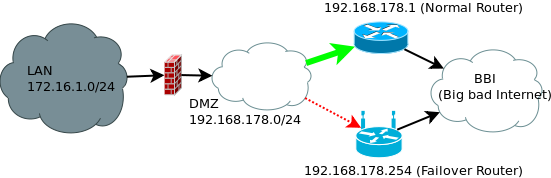
我希望不仅能够检测其中一台路由器是否出现故障(使用 iproute2 很容易),而且还能够检测它们的连接是否出现故障。两个路由器都没有 SNMP 或其他一些基于 RMON 的标准。
是否有类似于 ping 实用程序的东西,我可以在其中指定要使用的默认路由?
这样我就可以用一个小脚本以最佳方式监控两个链接。还是我应该走其他路线?
3
推荐指数
推荐指数
1
解决办法
解决办法
4248
查看次数
查看次数