我在 CentOS 5.8 最终服务器上运行了一个文件服务器。
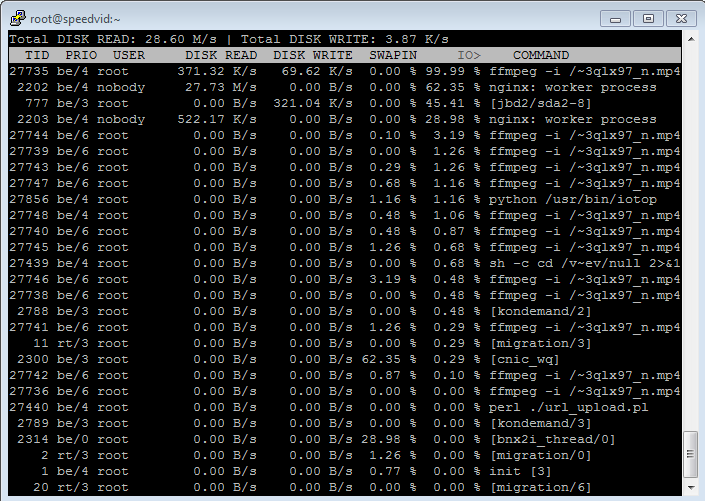
我目前唯一担心的是,由于jbd2/sda2-8进程,似乎是间歇性但持续的高磁盘 I/O 活动导致普遍放缓。
jbd2/sda2-8 使用/dev/sda2,它是第一个硬盘的第二个分区(即:根分区)。
更多信息:使用“iotop”的罪魁祸首似乎是“jbd2/sda1-8”每秒进行写入,如果我的谷歌搜索是正确的,这似乎是与 ext4 文件系统上的日志相关的内核进程。
我看到“jbd2/sda2-8”时不时地出现在这里,但肯定不是每 3 秒出现一次……当空闲时,它每分钟出现 1 到 2 次。当我使用系统时,它出现的频率更高。
ATOP 成绩:http : //grabilla.com/02b14-8022db2e-4eb9-4f10-8e10-d65c49ad7530.png
IOTOP 结果:http ://grabilla.com/02b14-cf74b25d-4063-4447-9210-7d1b9b70e25b.png
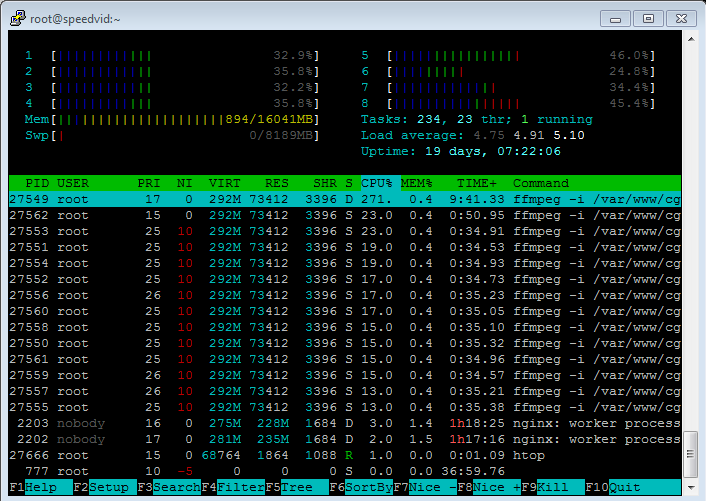
HTOP 结果:http ://grabilla.com/02b14-ad8cad0e-89b0-46d3-849d-4fd515c1e690.png
jbd2/sda2-8 是我看到的使用 iotop 在磁盘上写入的进程,即使它根本没有使用。
有人知道如何解决 jbd2/sda2-8 进程导致的高磁盘使用率吗?
我们最近收到了来自戴尔的许多服务器,所有这些服务器都在 BIOS 中禁用了硬件辅助虚拟化。
据我所知,硬件辅助虚拟化是一件好事——那么戴尔为什么要禁用它呢?如果机器不充当虚拟机主机,它是否有性能开销?是否存在任何安全问题?
如果它与您的答案相关,我们将主要使用:
我正在寻找一种快速可靠的排队系统,它可能可以跨机器分布。平台是Linux。开源是首选。
RabbitMQ 和 ZeroMQ 看起来都不错,但我没有使用这些或任何其他排队系统的经验。你能为我指出正确的方向吗?
在CPU 时间的维基百科页面中,它说
CPU 时间以时钟滴答或秒为单位测量。通常,将 CPU 时间衡量为 CPU 容量的百分比很有用,这称为 CPU 使用率。
我不明白如何用百分比代替持续时间。当我查看时top,没有%CPU告诉我MATLAB使用的是 2.17 个内核吗?
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18118 jasl 20 0 9248400 261528 78676 S 217.2 0.1 8:14.75 MATLAB
题
为了更好地理解CPU使用率是什么,我如何自己计算CPU使用率?
我们正在从 1 个网络服务器设置转移到两个网络服务器设置,我需要开始在两台负载平衡机器之间共享 PHP 会话。我们已经安装(并启动)了memcached,所以我很高兴我可以通过只更改文件中的3 行(session.save_handler和session.save_path)来完成新服务器之间的共享会话:php.ini
我替换了:
session.save_handler = files
和:
session.save_handler = memcache
然后在主 Web 服务器上,我将session.save_path指向 localhost:
session.save_path="tcp://localhost:11211"
在从属网络服务器上,我将 设置session.save_path为指向主服务器:
session.save_path="tcp://192.168.0.1:11211"
工作完成,我测试了它并且它有效。但...
显然,使用 memcache 意味着会话在 RAM 中,如果机器重新启动或 memcache 守护进程崩溃,会话将会丢失 - 我对此有点担心,但我更担心两个网络服务器之间的网络流量(尤其是当我们扩大规模),因为每当有人负载平衡到从网络服务器时,他们的会话将从主网络服务器通过网络获取。我想知道是否可以定义两个,save_paths以便机器在使用网络之前查看自己的会话存储。例如:
掌握:
session.save_path="tcp://localhost:11211, tcp://192.168.0.2:11211"
奴隶:
session.save_path="tcp://localhost:11211, tcp://192.168.0.1:11211"
这会成功地跨服务器共享会话并帮助提高性能吗?即节省 50% 的时间网络流量。还是这种技术仅适用于故障转移(例如,当一个内存缓存守护进程无法访问时)?
注意:我并不是特别询问内存缓存复制 - 更多关于 PHP 内存缓存客户端是否可以在池中的每个内存缓存守护进程内达到峰值,如果找到一个会话,则返回一个会话,如果没有找到,则只创建一个新会话在所有商店。在我写这篇文章的时候,我想我对 PHP 的要求有点高,哈哈...
假设:没有粘性会话、循环负载平衡、LAMP 服务器。
假设连接是通过 LAN 1Gbe 或 10Gbe 连接,可以在生产服务器上合理地使用 NFS 作为将计算服务器连接到存储服务器的方法吗?
显然有一些网络开销,如果启用了同步模式,NFS 在写入时似乎特别慢。否则它看起来相当轻巧,并且能够根据我的说法进行扩展,但我个人对此几乎没有经验。我错了吗?
问题是我现在有一个服务器既充当存储服务器又充当 Web 服务器,但我最终可能在将来需要将两者分开,并考虑到某些请求需要通过 Web 应用程序层进行身份验证在初始化文件传输之前,这个软件有点棘手。网络 fs 挂载是我最简单的选择……不知道这是否合适。
我还计划尝试使用 NFS 的本地缓存,这应该可以大大提高性能,但我不确定这是否足够。
至于替代方案,我知道只有 iSCSI 是真正的竞争对手,而且大多数人似乎都推荐 NFS,而不是其他任何鲜为人知的产品。
我们这里有 HP 笔记本电脑在工作,我们的政策是开启 HP 的硬盘加密以在丢失/被盗的情况下保护客户端数据库和 IP。
我想知道在这种情况下是否有任何性能下降的证据?这些机器主要用作开发工作站。这里的轶事证据表明机器速度较慢。
我们是否应该使用另一种方法(即只加密敏感数据而不是整个磁盘)?
x86/x64 虚拟化(我可能会使用 VirtualBox,可能是 VMWare,绝对不是半虚拟化)对于使用 Intel 硬件虚拟化的 Win64 主机和 Linux64 客户机的以下每个操作有多少开销?
纯粹受 CPU 限制的用户模式 64 位代码
纯粹受 CPU 限制的用户模式 32 位代码
到硬盘驱动器的文件 I/O(我主要关心吞吐量,而不是延迟)
网络输入/输出
线程同步原语(互斥体、信号量、条件变量)
线程上下文切换
原子操作(使用lock前缀,比较和交换之类的东西)
我主要对硬件辅助 x64 案例(Intel 和 AMD)感兴趣,但也不介意听到有关无辅助二进制转换和 x86(即 32 位主机和来宾)案例的信息。我对半虚拟化不感兴趣。
我有一个 Linux Centos 系统,它挂载了一些 NFS 共享,从该共享读取和写入文件时,我可以使用什么技术来测量 I/O 速度/延迟/速率?这种技术是否也可以应用于本地硬盘以进行比较?
最近我的朋友告诉我,在有足够内存的 linux 网络服务器上关闭交换是个好主意。我的服务器有 12 GB,目前在峰值负载下使用 4 GB(不包括缓存和缓冲区)。
他的论点是,在正常情况下,服务器永远不会使用其所有 RAM,因此它遇到 OutOfMemory 情况的唯一方法是由于某些错误/ddos/等。因此,如果关闭交换,系统将耗尽内存,最终会导致占用内存的程序(很可能是 Web 服务器进程)和其他一些进程崩溃。如果打开了交换它会同时占用 RAM 和交换空间,最终会导致同样的崩溃,但在此之前,它会卸载关键进程(如 sshd)进行交换,并开始执行大量交换操作,从而导致速度大幅下降。这样,当在 ddos 系统下可能会由于巨大的滞后而进入完全无法使用的状态时,我可能无法登录并终止网络服务器进程或拒绝所有传入流量(除了 ssh)。
这是正确的吗?我是否遗漏了什么(例如,即使我有足够的 RAM,交换分区在某些方面也非常有用)?我应该关掉它吗?
performance ×10
linux ×2
nfs ×2
web-server ×2
64-bit ×1
centos5 ×1
cpu-usage ×1
dell ×1
encryption ×1
hard-drive ×1
lamp ×1
memcached ×1
nginx ×1
php ×1
security ×1
storage ×1
swap ×1
ubuntu ×1
x86 ×1
{kind=link}
{kind=link}
{kind=link}