标签: linux-kernel
如果在上电之前插入 USB 设备,我们的嵌入式 linux 系统将无法识别它。建议?
我们正在小型嵌入式设备上进行开发。该设备是一个运行 OpenEmbedded linux 的 gunstix overo 板。我们的开发几乎已经完成,并且遇到了我们无法弄清楚的最奇怪的错误。
我们有一个 USB 设备(分光光度计),它有一个 USB2.0 连接和一个用于光源的外部电源。典型的行为是插入电源,然后通过 USB 连接到主机。当设备检测到 USB 连接时,设备启动并启用光源和风扇。然后该设备可以被主机系统使用。
问题是,如果在我们打开 Gumstix 之前将设备插入 Gumstix,USB 设备显然没有被系统探测到(因此不会打开)。在正常情况下,当通过插入 USB 电缆初始化连接时,光谱会自行打开并可供系统使用(这通常可以通过“lsusb”看到)。这些事情都没有发生。没有通过“lsusb”检测到设备,也没有我们可以看到的任何类型的 dmesg 错误。 就好像设备没有插入一样。
如果我们拔下 USB 电缆并在系统启动后将其重新插入,该设备确实会显示并正常工作。它打开并显示在 USB 总线上,我们可以通过我们的驱动程序访问它。
在任何其他台式机或笔记本电脑上,当我们插入光谱仪时,主机系统是打开还是关闭都没有关系。这种行为是我认为是“正常的”——USB 系统在启动时被探测和初始化,并且 USB 设备上线。换句话说,只要我们在系统启动后插入 USB 设备,我们的系统就可以正常运行。不幸的是,这在我们的最终产品中是不可能的——一切都是同时发生的。
附加信息:1) 我们尝试在系统关闭时将闪存驱动器连接到系统。正如预期的那样,启动系统会使闪存驱动器联机 2) 没有关于光谱或 USB 设备的消息(使用 dmesg)。“lsusb”仅列出 USB 集线器/控制器。从字面上看,就好像设备不存在且未插入。 3) 我们尝试了来自gumstix 的全新图像和去年的旧图像。两张图都有这个问题。我们使用的所有 3 种 gunstix 设备都存在此问题。
有没有人有什么建议?据我所知,完全模拟 USB 设备的“拔出”和“重新插入”是不可能完全“重新启动”USB 系统的。我觉得正在发生的事情是 USB 总线上没有初始探测会触发 USB 握手,但这在某种程度上特定于光谱。这似乎是内核问题,或者至少是内核如何初始化 USB 子系统的问题。我不太确定。
我已经尝试过gumstix 邮件列表,但之前似乎没有人见过这个问题。关于从哪里开始寻找的任何建议或建议都会很棒。
谢谢!布莱恩
output etc.
$ uname -a
Linux overo 2.6.33 #1 Tue …推荐指数
解决办法
查看次数
无需重启即可更新内核
与此问题中涉及的一些主题类似,内核更新后重新启动 Linux 是否重要?,我很好奇是否有一种方法可以在不重新启动的情况下将内核更新应用到系统。我知道有一家名为Ksplice的供应商提供此类功能。但是,我很好奇是否有一种方法可以在没有商业产品的情况下执行相同的任务,或者可能是 Ksplice 的替代品,因为看起来某些功能集自 Oracle 购买以来可能已经发生了变化。理想情况下,如果有一个脚本或方法可以添加一些文件以在 CentOS、Red Hat 和/或 Ubuntu 上执行此操作,那就太好了。
推荐指数
解决办法
查看次数
Linux: echo 3 > /proc/sys/vm/drop_caches 需要几个小时才能完成
我有一个 Thecus N8900 NAS,它是一个基于 Linux 的文件服务器,通过 NFS 向六个客户端提供文件。由于某些原因,色卡司支持尚未解释,它运行一个脚本,每 60 秒检查一次 /proc/meminfo,如果磁盘缓存超过可用 RAM 的 50%,它们会执行“echo 3 > /proc/sys/vm/drop_caches " 命令来刷新缓存。
撇开这是否有意义的问题不谈,实际的“echo 3 > /proc/sys/vm/drop_caches”命令可能需要几个小时才能完成,这对我来说似乎太长了。
最大的问题是,当这种情况发生时,机器上的负载会激增,磁盘利用率也是如此,这使得所有 NFS 流量都会爬行,直到命令最终完成,此时事情又会再次响应。
NAS 本身有 16 gig 的 RAM、7 个采用 raid6 配置的驱动器(加上一个热备用),根本没有驱动器问题(根据 SMART 测试)。
所以问题是:什么会导致 drop_caches 命令花费这么长时间?
推荐指数
解决办法
查看次数
为什么我的 Linux 内核无法回收其平板内存?
我有一个系统,它的内存使用量不断增加,直到达到了即使对于平常的事情也会发生交换的程度,从而变得非常无响应。罪魁祸首似乎是内核分配的内存,但我很难弄清楚内核中究竟发生了什么。
我如何知道哪些内核线程/模块/什么负责特定的内核内存块使用?
下面是系统内存使用情况随时间变化的图表:

该slab_unrecl值随时间增长,对应于SUnreclaim中的字段/proc/meminfo。
当我跑到slabtop该图的末尾并按缓存大小对其进行排序时,它向我展示了以下内容:
Active / Total Objects (% used) : 15451251 / 15530002 (99.5%)
Active / Total Slabs (% used) : 399651 / 399651 (100.0%)
Active / Total Caches (% used) : 85 / 113 (75.2%)
Active / Total Size (% used) : 2394126.21K / 2416458.60K (99.1%)
Minimum / Average / Maximum Object : 0.01K / 0.16K / 18.62K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
3646503 …推荐指数
解决办法
查看次数
调试 kmalloc-64 板分配/内存泄漏
我有两个配置非常相似的虚拟服务器:Debian bullseye(测试)、5.6.0 内核、512 MB RAM。它们都运行相似的工作负载:MySQL、PowerDNS、WireGuard、dnstools.ws 工作线程和用于监控的 Netdata。
仅在其中一台服务器上,不可回收的平板内存会随着时间线性增长,直到达到最大值(当服务器的内存已 100% 分配时):
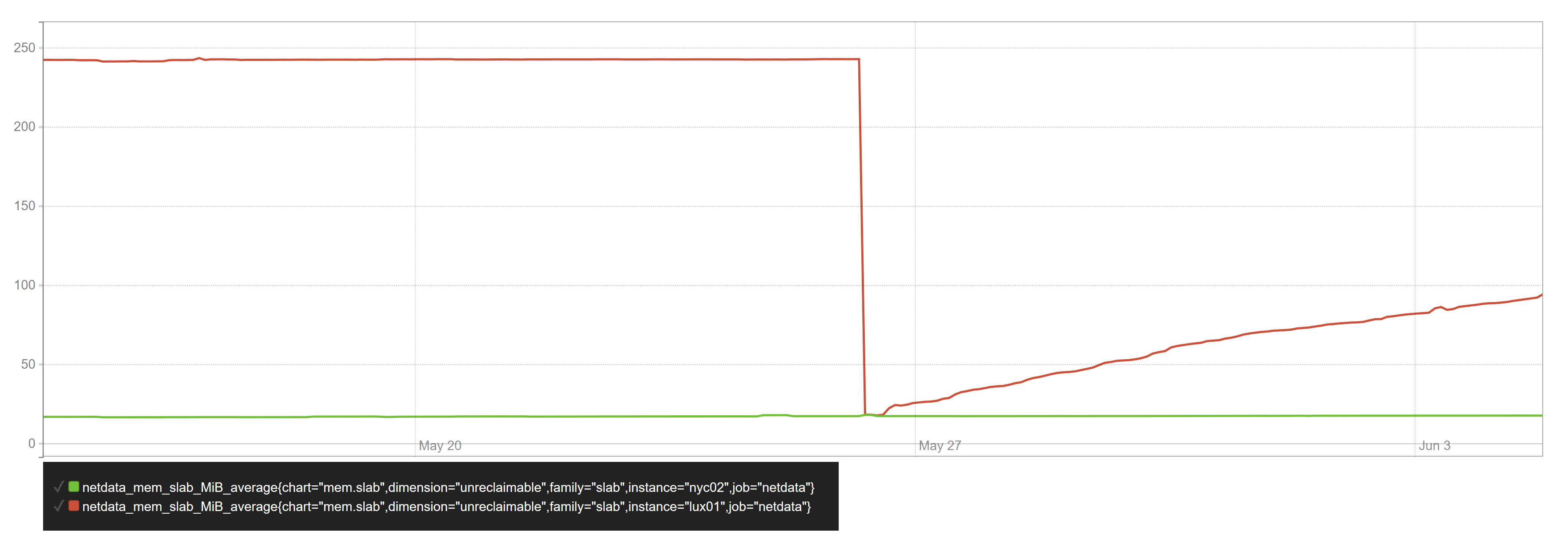
下降是当我重新启动 VPS 时。
slabtop在坏服务器上:
Active / Total Objects (% used) : 1350709 / 1363259 (99.1%)
Active / Total Slabs (% used) : 25358 / 25358 (100.0%)
Active / Total Caches (% used) : 96 / 124 (77.4%)
Active / Total Size (% used) : 113513.48K / 117444.72K (96.7%)
Minimum / Average / Maximum Object : 0.01K / 0.09K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE …推荐指数
解决办法
查看次数
为什么 224.0.0.1 流量会被 Linux 主机过滤?
当向目标地址(例如 )发送 ICMPv4 echo 请求时224.0.0.1,接收请求的 Linux 主机会忽略该请求。使用的目标 MAC 地址是01:00:5e:00:00:01。
让这些 Linux 主机应答的唯一方法是将 Kernel 参数设置net.ipv4.icmp_echo_ignore_broadcasts为 value 0。这将指示内核响应多播和广播 ICMPv4 请求,并为广播安全威胁打开大门。
为什么组播流量通过该参数过滤?有任何攻击可以证明其合理性吗?
使用 ICMPv6 和等效目标地址(如 )ff02::1,流量不会被 Linux 主机过滤。未来是否存在被过滤的风险?ICMPv4 是否存在 ICMPv6 不存在的威胁?
Linux 主机:
- Linux 发行版:Ubuntu 20.04.1 LTS Focal
- Linux内核:5.4.0
推荐指数
解决办法
查看次数
如何在AWS EC2上获取最新的内核包
我管理一些运行 Amazon Linux(不确定是什么版本)的 EC2 实例,这些实例需要安全补丁。
很多软件都打了很好的补丁,但我们一直停留在内核升级上。我们无法按照我们的意愿使用最新的内核版本。我们做了什么?
- 通过执行从 Amazon 存储库获取最新的内核版本
yum update。系统报告我们已经获得了预期的最新内核版本,并且不再需要更新任何内容。 - 获得最新的内核版本后,我们通过单击 EC2 控制台上的“重新启动”来重新启动 EC2。EC2重启后,我们使用命令检查了EC2的内核版本
uname -r。它报告我们仍然使用相同的内核版本,而不是我们期望的最新内核版本。
我们错过了什么要点?请帮忙。
kernel amazon-ec2 linux-kernel amazon-web-services amazon-linux
推荐指数
解决办法
查看次数
PostgreSQL 无法启动,因为它“无法分配内存”
我在 Ubuntu 10.04 上运行 PostgreSQL 8.4.5。我运行了一个 EC2 实例,其中有几个站点在 nginx 上运行。大多数这些站点在 Django 上运行并连接到这个 Postgres 实例。
出于某种原因,今晚 8 点 45 分,Postgres 宕机了。我登录到机器,我看到这个错误信息:
* Starting PostgreSQL 8.4 database server
* The PostgreSQL server failed to start. Please check the log output:
2011-04-17 04:46:49 UTC FATAL: could not create shared memory segment: Cannot allocate memory
2011-04-17 04:46:49 UTC DETAIL: Failed system call was shmget(key=5432001, size=16211968, 03600).
2011-04-17 04:46:49 UTC HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded available …推荐指数
解决办法
查看次数
关于Page Cache和dirty_background_bytes的误解
我已经研究了一段时间了,但事情并不符合我的期望,但我不知道是因为有什么不对,还是我的期望是错误的。
所以,我有一个内存超过 100GB 的系统,我将我的内存设置dirty_background_bytes为 9663676416(9GB)和dirty_bytes两倍(19327352832 或 18GB)
在我看来,这应该让我最多可以将 9GB 写入文件,但实际上它只是位于内存中,不需要访问磁盘。Mydirty_expire_centisecs是默认值3000(30 秒)。
所以当我运行时:
# dd if=/dev/zero of=/data/disk_test bs=1M count=2000
并跑了:
# while sleep 5; do egrep 'Dirty|Writeback' /proc/meminfo | awk '{print $2;}' | xargs; done
(以 kb 为单位打印脏字节,以 kb 为单位打印回写,在 5 秒快照时以 kb 为单位打印 WritebackTmp)
我本来希望看到它转储 2GB 到页面缓存中,在那里等待 30 秒,然后开始将数据写入磁盘(因为它从未超过 9GB 背景比率)
相反,我看到的是:
3716 0 0
4948 0 0
3536 0 0
1801912 18492 0
558664 31860 0
7244 0 0
8404 0 …推荐指数
解决办法
查看次数
如何转储失败的系统调用的内核堆栈跟踪?
这是一个规范问题。我想了解为什么特定的系统调用失败。是否可以显示系统调用的内核堆栈跟踪:
- 当返回非零或负数时(这取决于系统调用来知道它何时失败,也许我们应该将失败基于
errno) - 当执行到达返回指令时?
尝试使用trace/trace-bpfcc来自bcc-tools(Fedora)/ bpfcc-tools(Ubuntu):
$ sudo /usr/sbin/trace-bpfcc -K 'r::do_sys_open "%llx", retval'&
$ touch /root # As normal user
15979 15979 touch do_sys_open fffffffffffffffe
kretprobe_trampoline+0x0 [kernel]
do_syscall_64+0x5a [kernel]
entry_SYSCALL_64_after_hwframe+0x44 [kernel]
但堆栈跟踪毫无意义。
推荐指数
解决办法
查看次数
标签 统计
linux-kernel ×10
linux ×7
kernel ×3
amazon-ec2 ×1
amazon-linux ×1
embedded ×1
icmp ×1
io ×1
ipv4 ×1
low-memory ×1
memory ×1
multicast ×1
nfs ×1
performance ×1
postgresql ×1
usb ×1