nh2*_*nh2 1 networking performance ethernet ping latency
我有 2 台服务器位于运行 Ubuntu 16.04 的机架中,它们之间有 1 米长的以太网电缆,都具有标准的英特尔以太网适配器。
两者ping之间大约是300 us(微秒)。
这是我在大多数千兆以太网设置中看到的标准延迟。
但是与理论限制相比,这种延迟似乎仍然很高;为什么?我读过 1 GbE 可以实现 40 us 的延迟。
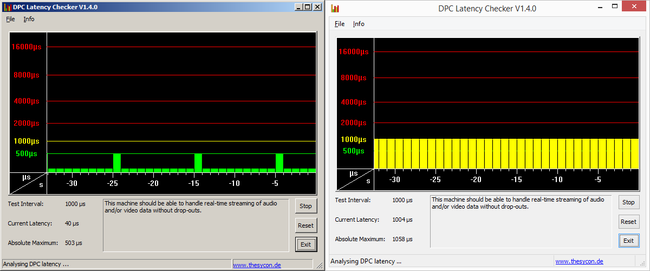
这是我可以预期的最小延迟,还是我可以执行软件调整来减少这种延迟?瓶颈是什么?是Linux吗?在这个适用于 Windows的游戏玩家网站上,屏幕截图中的工具在大多数情况下似乎表明延迟为 40 us,但这对我的 Linux 服务器并没有多大帮助。
(如何)我可以让我的ping40 个我们?
编辑:在寻找的截图再次,它可能是我们出的40是不实际的往返时间,但它实际上是Windows内核中的特定的延迟,因此40我们可能只是部分的总往返时间,这可能更高,未列出。这也符合这里的答案。
(我最初是在超级用户处问这个问题的;此时我不清楚 ServerFault 是一个更合适的社区来询问网络性能问题,而且我在那里没有足够的声誉来提出这个问题,所以我重新提出在这里。我也将硬件切换到服务器硬件。)
Zac*_*c67 11
Aping既不测量延迟也不测量往返时间。它测量 ICMP 回显请求响应时间。ICMP消息以低优先级,并采取运行方式不是严重的交通时间。
正如@barbequesauce 指出的那样,双绞线需要一些复杂的编码,因此 1000BASE-T NIC 的编解码器每边至少需要 10 µs(加上系统总线和 IRQ 延迟)。双绞线 cat.6 的速度系数为 65%(~200,000 km/s),因此每 10 m 增加 0.05 µs 或 50 ns。光纤并不是真的更快(VF 为 67%),但使用更简单的编码,每边可能是 5 µs,而不是 10 µs。
IP 堆栈将为您的延迟预算增加一些微秒。在一个快速的系统上,你可能会逃脱大约 20 µs。
当然,NIC、您的系统总线和 IP 堆栈的确切值取决于您的硬件和软件。上面的数字是你所能得到的。并且不用于ping测量。
简而言之,您肯定没有真正的问题,问题在于解释ping输出。
{kind=link}